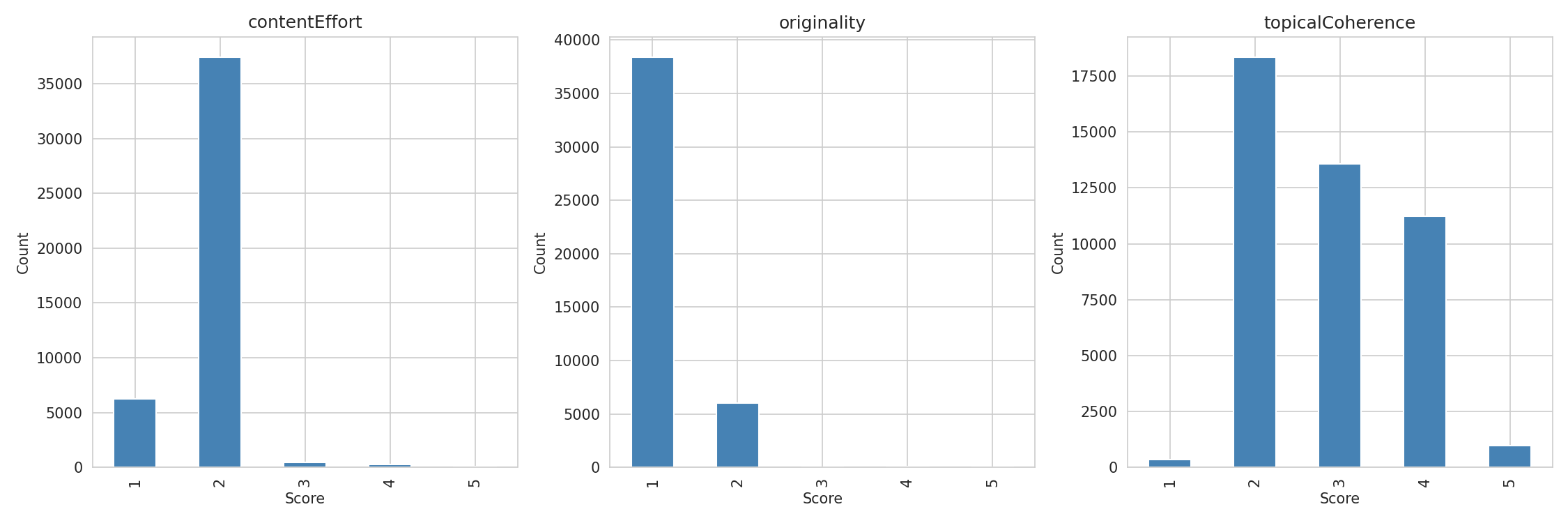
LLMベースのコンテンツ品質ルーブリックを使用して、2,212の米国キーワードにわたる44,465のSERP結果をスコアリングし、ドメインオーソリティを制御した後、それらのスコアがGoogleのランキングを予測するかどうかをテストしました。以下がその発見です。
データでは誰も答えられない質問
SEO業界は一種の信仰で動いています:素晴らしいコンテンツを作ればランクインする。Google自身のガイドラインもそう言っています。しかし、「ドメインオーソリティと比べて、コンテンツ品質は実際にどれほど重要か?」と尋ねると、誰もデータを持っていません。
私はそれを確かめることにしました。
私が行ったこと
私は、以下の単純な仮説を検証するためのパイプラインを構築しました:
H1: ドメインオーソリティを制御した後、コンテンツ品質スコアはSERP順位と負の相関がある(品質が高い → 順位が高い)。
データセット
- 2,212の米国キーワード (Ahrefsより、情報提供型+商業意図、非ブランド)
- 各キーワードの上位30結果(Serper API経由)
- 60,409のSERP結果をクロールし、rs-trafilaturaを使用してマークダウン形式で抽出
- 抽出品質でフィルタリング後、44,465ページをスコアリング
- 8,169のユニークドメインのドメインオーソリティ(DataForSEO Backlinks API経由)
スコアリング手法
大規模なスコアリング前に、MiMo-V2-FlashとClaude Opus 4.6を比較する150ページのパイロットテストを実施しました。一致率は高く(Spearman ρ = 0.766、Cohen's κ = 0.747)、そのまま進めることにしました。各ページは3つの次元でスコアリングされました:
| ルーブリック | 基づくもの | 測定する内容 |
|---|---|---|
| コンテンツ努力 | Googleが流出した contentEffort シグナル | このコンテンツにどれだけの真の努力が投入されたか?AIが数分で複製できるか? |
| 独自性 | Googleが流出した originalContentScore シグナル | これは新しい知識を追加するか、それとも既存の情報を再編成するだけか? |
| トピック一貫性 | Googleの page2vecLq シグナル | 各セクションは核心トピックに役立つか、それともページが脱線するか? |
各ルーブリックは1〜5でスコアリングされ、キャリブレーションルール、具体例、およびいくつかのクライアント案件で洗練してきた誤検知対策が適用されています。重要なのはモデルではなくルーブリックです — スコアリングプロンプトは十分に詳細なので、能力のあるLLMならどれでも同様の結果を生成し、それがパイロットで2つの非常に異なるモデル間で強い一致を示した理由です。自身のコンテンツをスコアリングしたい場合は、具体例付きの完全なルーブリックを別途公開しています。
統計的有意性に関する注意点
44,000観測点では、統計的有意性は極めて簡単に達成されます — ごく小さな、意味のない効果でも p < 0.001 を示します。そのため、p値ではなく、効果の大きさ、実用的な有意性、および発見が複数の方法で一貫して成り立つかに焦点を当てます。実践的に重要でないほど効果が小さければ、「統計的有意」でも気にしません。
分析方法
私は単一のテストに依存しませんでした。8つの独立した方法を用いて三角測量を行いました。方法3と5は入れ子構造(同じキーワードを争う複数のページは独立していない)を適切に扱います。他の方法は扱わないので、それらのp値にはその前提条件が伴います:
- Spearman順位相関
- 偏Spearman相関(ドメインオーソリティを制御)
- キーワード内順位分析(同じクエリを争うページを比較)
- 順列検定(1,000回シャッフルによるゴールドスタンダードなp値)
- 線形混合効果モデル(入れ子構造を扱う)
- クラスター標準誤差付きOLS
- トップ10確率のロジスティック回帰
- SHAP特徴量重要度付きランダムフォレスト
結果
はい、コンテンツ品質はランキングを予測する — だがどれほど?
8つの方法すべてが同じ方向を示しました。ドメインオーソリティを制御した後でも、コンテンツ品質は高いランキングと関連しています。
しかし、重要なのはp値ではなく、効果の大きさです。
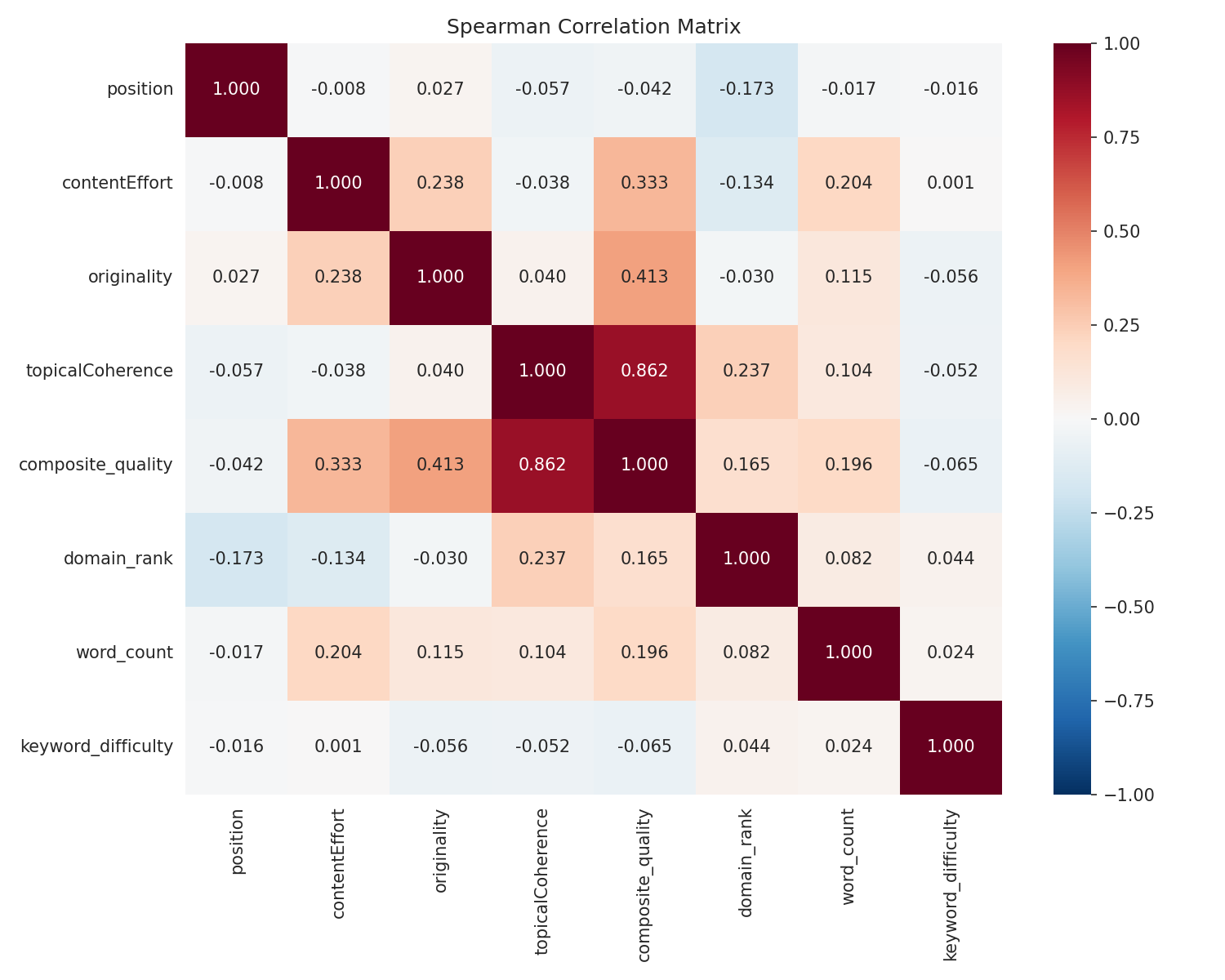
ドメインオーソリティは10倍重要
ランダムフォレスト(35,621ページで学習、8,844ページのホールドアウト検証、R² = 0.178)はそれを明白にします:
| 特徴量 | 重要度 |
|---|---|
| ドメインオーソリティ | 49.7% |
| 単語数 | 31.6% |
| キーワード難易度 | 11.8% |
| トピック一貫性 | 3.7% |
| コンテンツ努力 | 1.7% |
| 独自性 | 1.5% |
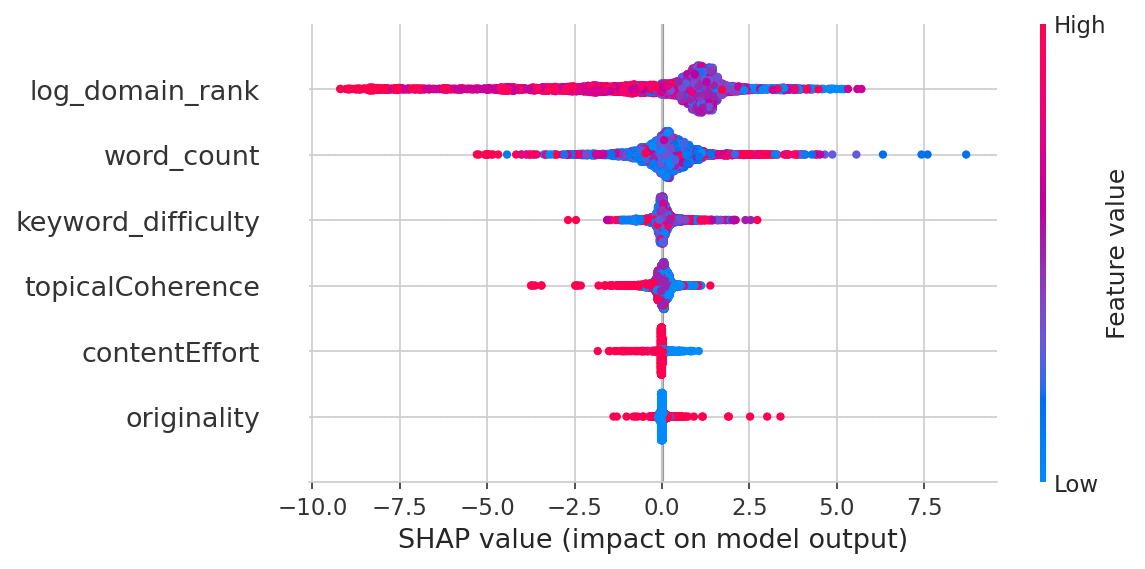
ドメインオーソリティ単独でランキング変動の半分を説明します。コンテンツ品質は合わせて約7%です。そして、完全なモデルでも起こっていることの18%しか説明できません — 残りの82%は測定しなかった要因(ページレベルのバックリンク、ユーザーエンゲージメント、Core Web Vitals、ブランドシグナルなど)です。参考までに、公開されているSEOランキングファクター研究では通常、R²値が0.10-0.25と報告されます。Googleのランキング決定の大半を説明するモデルはありません — もしそうなら、我々は皆引退しているでしょう。
しかし、その7%は実在し一貫している
8つの方法すべてで、シグナルは確かです:
| 方法 | 発見 | p値 |
|---|---|---|
| Spearman(生データ) | トピック一貫性: ρ = -0.057 | p < 0.001 |
| 偏Spearman相関(DA制御) | 依然として存在: ρ = -0.017 | p < 0.001 |
| キーワード内分析 | 中央値 ρ = -0.066, 60.5%のキーワードで品質が順位を予測 | ブートストラップ信頼区間: [-0.080, -0.051] |
| 順列検定 | 帰無仮説から11標準偏差離れている | p < 0.001 |
| 混合効果モデル | 一貫性ポイントあたり-0.23順位 | p < 0.001 |
| クラスター化OLS | 複合ポイントあたり-0.51順位 | p < 0.001 |
| ロジスティック(トップ10) | 一貫性ポイントあたり+4.7%オッズ | p < 0.001 |
分布の仮定をせず、入れ子構造を適切に扱う順列検定は、これを疑いの余地なくします。
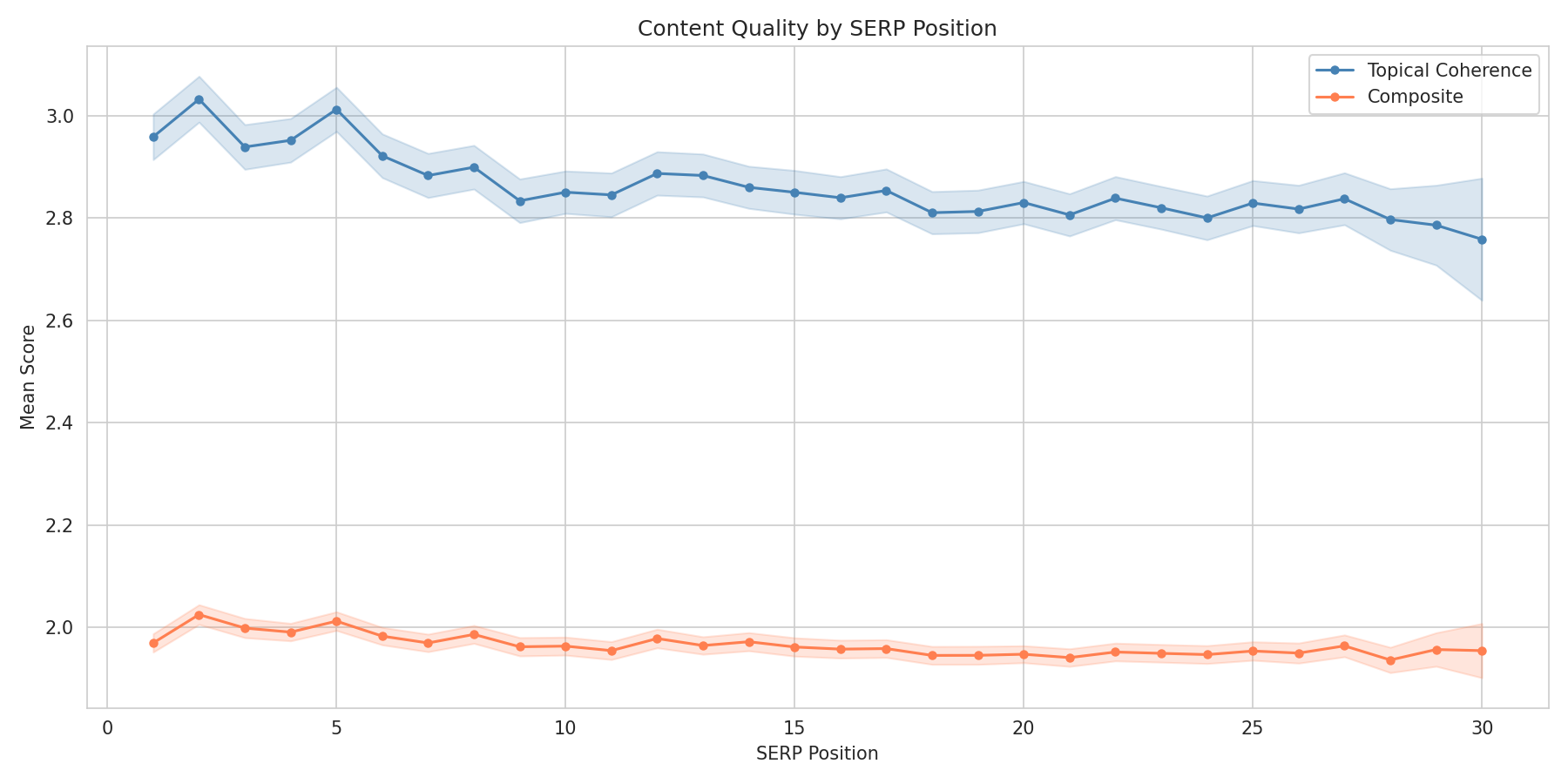
トピック一貫性の効果
3つの次元の中で、トピック一貫性がランクとの最も明確な関連を示しました。トピックに留まるページは、全てを網羅しようとするページよりも高くランクします。
| トピック一貫性スコア | 平均順位 | トップ10率 |
|---|---|---|
| 1(一貫性なし) | 15.27 | 32.0% |
| 2(焦点が合っていない) | 14.53 | 34.9% |
| 3(適切) | 14.27 | 36.1% |
| 4(よく焦点が合っている) | 13.52 | 40.2% |
| 5(非常に焦点が合っている) | 12.27 | 47.2% |
トピック一貫性でスコア5のページはトップ10率が47.2%で、スコア1の32.0%に対し、15ポイントの差があります。注意:スコア5はN=980、スコア1はN=338なので、これらの裾の推定値は中間スコアよりも広い信頼区間を持ちます。
重要なニュアンス
コンテンツ品質は、権威を持たないときに最も重要
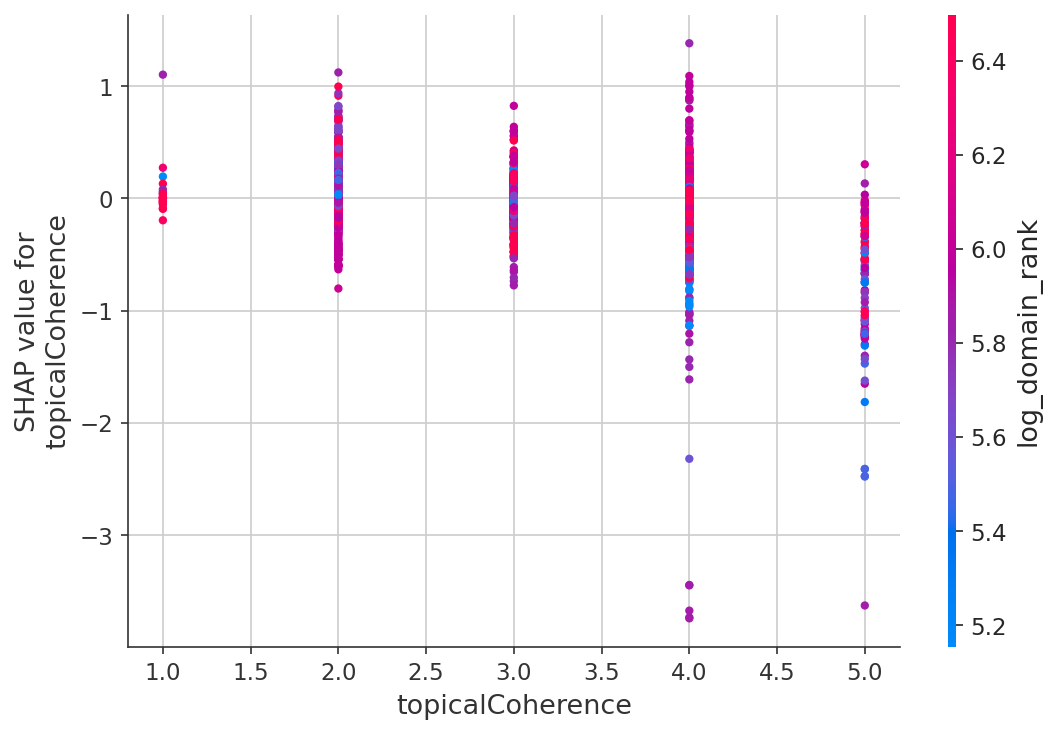
これが最も興味深い発見でした。データをドメインオーソリティの四分位で分割しました:
| ドメインオーソリティ | 一貫性 → 順位 ρ | 有意か? |
|---|---|---|
| Q1(権威が最も低い) | ρ = -0.059 | はい (p < 0.001) |
| Q2 | ρ = -0.035 | はい (p < 0.001) |
| Q3 | ρ = +0.018 | いいえ |
| Q4(権威が最も高い) | ρ = +0.011 | いいえ |
![]()
権威の低いドメインでは、コンテンツ品質は真の差別化要因です。権威の高いドメインでは、ほとんど関係ありません — 品質に関わらずランクインします。
単純に言えば: もしあなたがForbesなら、平凡なコンテンツを公開してもランクインします。もしあなたがスタートアップなら、コンテンツ品質は実際に持っている数少ないレバーの一つです。
より大きな予算があれば行いたいこと: 44,000 URLのページレベルバックリンクデータは予算の範囲外だったため、ドメインレベルのオーソリティを使用しました(将来的にこれを再検討するかもしれません)。ドメインオーソリティは鈍器です — サイトが強いかは教えてくれますが、この特定のページがリンクを獲得したかは教えてくれません。ページレベルの参照ドメイン数があれば、努力の高いコンテンツがページレベルでより多くのバックリンクを集めるか、そして品質→ランク効果が直接シグナルではなくリンク獲得を通じて機能するかどうかをテストできます。それは次に検討したいことです。
情報提供型キーワードではコンテンツが重要
検索意図による効果の違いをテストしました:
| 意図 | キーワード内 ρ | 効果を示すキーワードの割合 |
|---|---|---|
| 情報提供型のみ | -0.101 | 65% |
| 商業的+情報提供型 | -0.041 | 56% |
その差は明確です(Fisherのz検定、p < 0.001)。コンテンツ品質は、商業的クエリよりも情報提供型クエリで2.5倍以上重要です。
簡単なキーワードは品質をより報いる
| キーワード難易度 | キーワード内 ρ | 負の相関を示す割合 |
|---|---|---|
| KD 0-20(簡単) | -0.080 | 63% |
| KD 21-40 | -0.081 | 64% |
| KD 41-60 | -0.048 | 56% |
| KD 61+(難しい) | -0.007 | 51% |
競争の激しいキーワードでは、権威が完全に支配するため、コンテンツ品質はほとんど効果がありません。競争の少ないキーワードでは、品質が実際に重要です。
機能しないもの:キーワード詰め込み
ここで一つの注意点は、検索語に対してプライマリインデックスに含まれるための関連性のゲートとして想定されるGoogleのBM25が、長年にわたって進化してきたことです。私は標準的なBM25スコア(キーワード関連性/密度)を実行し、予期しなかったものを見つけました:
| 順位帯 | 平均BM25スコア |
|---|---|
| トップ1-5 | 3.950 |
| 6-10 | 3.967 |
| 11-20 | 4.016 |
| 21-30 | 4.056 |
より高くランクするページは、わずかに低いキーワード密度を持ちます。 キーワード内分析もこれを確認しました:BM25は順位と正の相関があり(ρ = +0.045)、よりキーワードが詰め込まれたページはより悪くランクすることを意味します。
考えてみれば納得がいきます。トップランクのページは、トピックを自然にカバーする権威あるドメインである傾向があります。低ランクのページは、しばしばキーワードを過剰に最適化したサービスページです。
---## コンテンツ戦略における意味 多くのSEO担当者にとって、これは少しばかり
「つまり、水は濡れていると言っているわけね」
という瞬間であり、その通りだと言えるでしょう。
ドメインオーソリティが低い場合(中央値未満)
- コンテンツの質は最高のレバーの一つです。 焦点が明確で首尾一貫した記事は、散漫で焦点が定まっていないコンテンツよりも、測定可能なほどランキング上位を獲得する可能性が高くなります。
- トピックの一貫性が最も重要です。 1ページにつき「1つのトピック」を選び、きちんと解説してください。1つの「究極のガイド」で5つのキーワードにランクインさせようとしないでください。
- 情報提供型で、競合性(KD)が低いキーワードをターゲットにしてください。 そこが、コンテンツの質が最も強い効果を発揮する領域です。
ドメインオーソリティが高い場合
- コンテンツの質による効果は逓減していきます。 あなたのオーソリティ自体がすでにランキングを獲得させています。コンテンツを磨き上げることに伴う限界的な効果は小さいものです。
- オーソリティの維持に集中してください — 記事を書き直すことよりも、バックリンク、ブランド、信頼のシグナルの方が重要です。
すべての人に言えること
- キーワードの詰め込みをやめましょう。 むしろ少し逆効果です。
- 集中力は労力を上回ります。 焦点が定まり一貫性のあるページは、たとえその作成により多くの労力を要したとしても、長くても散漫なページよりも上位にランクインします。
コンテンツへの労力については?
この点は別途議論する価値があります。私は、通常の範囲(スコア1〜2)内では、コンテンツ労力スコアとランキングとの間に有意な相関関係を見いだせませんでした。しかし、ページの84%がスコア2、14%がスコア1を獲得しており、基本的に「低労力」と「非常に低労力」を比較していたことになります。上位30位内のページで、独自データ、独自調査、または文書化された専門知識を含むページはわずか1.8%でした。
これは、労力が重要かどうかについての発見というよりは、本物の労力がいかに稀であるかについての発見です。高労力のコンテンツは検索結果に極めて珍しく、その効果を測定するのに十分な量が単純になかったのです。
私の作業仮説 — このデータでは証明できないが矛盾もしない — は、労力のランキングへの影響は バックリンクを通じて「洗浄」される というものです。高労力のコンテンツ(独自データ、専門家インタビュー、独自調査)は引用可能です。引用可能なコンテンツはリンクを集めます。リンクはドメインオーソリティを構築します。そしてドメインオーソリティは支配的なランキング要因です。ですから、労力は非常に重要かもしれないが、その効果は独立した品質シグナルとしてではなく、オーソリティ指標に現れるということです。
もし(私が)ドメインレベルではなくページレベルのバックリンクデータを持っていれば、高労力のページがより多くの参照ドメインを惹きつけるかどうかをテストできるでしょう。それが次の研究です。私の推測では、これらは強く相関しているはずです。
オリジナリティ:ウェブは派生している
上位30位にランクインするページの86%はオリジナリティでスコア1(完全に派生したもの)を獲得しました。これはスコアリングの欠陥ではありません。Googleテストを自分で試してみてください:どんな情報提供型クエリでも検索し、上位10件の結果を読んで、他の9件では見つけられない主張を一つでも含むページがいくつあるか数えてみてください。ほとんどありません。
「平均以上」のオリジナリティに対するハードルは驚くほど低いのです。Googleは派生コンテンツに厳しいペナルティを課しているようには見えません — もし課しているとしても、そのペナルティはすでにオーソリティシグナルに組み込まれているのでしょう(オリジナルコンテンツ → 引用 → リンク → オーソリティ)。
私の見解では、LLMがますます多くのコンテンツ作成を担うにつれ、新しく独自のデータポイントと経験に基づく洞察の実証がより決定的な要因になるでしょう。しかし問題は、Googleなどがこれを大規模にどう測定できるか?ということです。
研究の限界
この研究には率直に認めるべき現実的な限界があります:
- LLMによるスコアリングは代替指標です。 これらのページをスコアリングしたのはGoogleの品質評価者ではなく、MiMo-V2-Flashです。LLMスコアはノイズの多い推定値ですが、パイロット検証(ベースラインOpusモデルに対してρ = 0.766, κ = 0.747)は、それらが合理的に一貫していることを示唆しています。
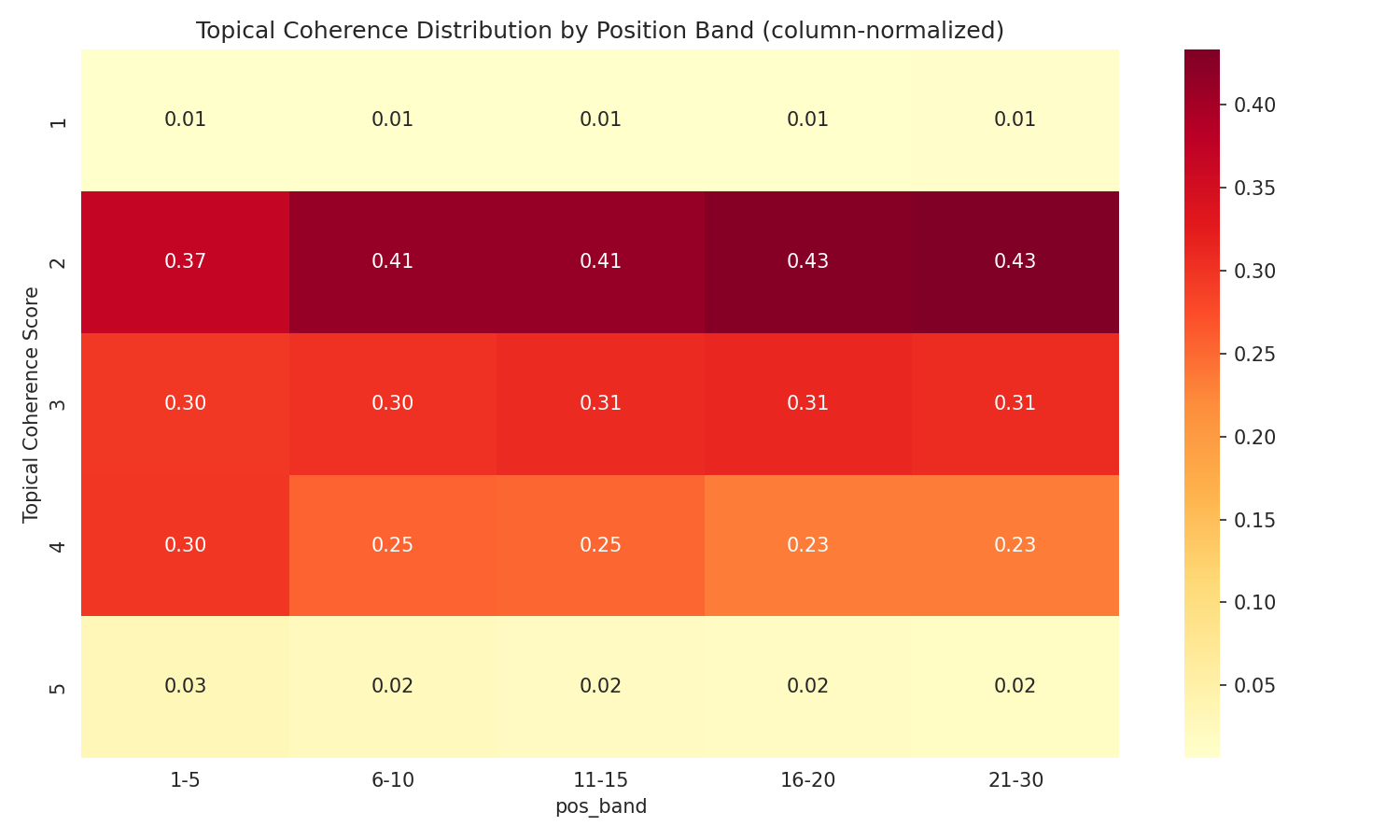
- 圧縮されたスコア分布。 ページの84%がコンテンツ労力でスコア2、86%がオリジナリティでスコア1を獲得しました。これはスコアリングの欠陥ではなく、ウェブの正確な反映です。ランキングするコンテンツのほとんどは独自データや独自調査を含んでいません。しかし、このことはそれらの評価基準に対する統計的検出力を制限しています。トピック一貫性は最も広い分布(スコア2が41%、スコア3が30%、スコア4が25%)を示し、最も強いシグナルを示しました — 部分的には、これがページ間で実際に違いが出る次元だからです。
- 横断的研究デザイン。 ランキングと品質をある一時点で測定しました。コンテンツ品質の向上がランキングの改善を 引き起こす ことを証明することはできません — 品質とランクに関連性があることしか示せません。
- 測定されていない交絡因子。 ドメインオーソリティ、語数、キーワード難易度を統制しましたが、測定されなかったランキング要因は多数あります:バックリンクの速度、ユーザーエンゲージメント、Core Web Vitals、ページ速度、ブランド検索など。ドメインオーソリティと語数も相関している可能性が高く(高オーソリティのサイトは長いコンテンツを制作する傾向がある)、語数の31.6%という特徴量重要度は部分的にオーソリティの代理指標かもしれない。
- コンテンツ抽出の品質。 rs-trafilaturaは記事をよく処理します(F1 0.93)が、商品ページやSPAを誤抽出することがあり、一部のページタイプではノイズを加える可能性があります。
- 標準的なBM25。 フィールド重み付け、近接性スコアリング、パッセージレベルスコアリングなしの基本的なOkapi BM25を使用しました。Googleの特許に沿ったBM25Fの実装では、おそらく異なる結果が得られるでしょう。
- 多重比較。 手法、評価基準、サブグループにわたって50以上のテストを実施しました。限界的な発見の中には、Bonferroni補正を経ても有意でないものがあるかもしれません。中核的な発見 — トピック一貫性の効果、DA四分位の交互作用、検索意図による違い — は、一貫した効果量を持つ複数の独立した手法で支持されました。
方法論の詳細
データ収集
- キーワード: Ahrefsから2,212の米国キーワード(ソフトウェア開発分野における情報提供型+商業意図型、非ブランドクエリにフィルタリング)
- SERPデータ: Serper API(キーワードあたり10件×3ページ = 上位30件の結果)
- HTMLダウンロード: httpx 並列処理(94%)、JSレンダリングページにはPlaywrightフォールバック(4%)
- コンテンツ抽出: rs-trafilatura(Rust, F1 0.966精度)
- ドメインオーソリティ: DataForSEO Backlinks Summary API(ドメインレベルランク、0-1000スケール)
スコアリング
- モデル: Xiaomi MiMo-V2-Flash (309B MoE, 15B 活性化パラメータ) via OpenRouter
- 3評価基準 × 44,465ページ = 133,395 APIコール
- LLMスコアリング総コスト: 約 $87
統計分析
- 一貫した結果が得られた8つの独立した手法
- 主要手法: キーワード内Spearman順位相関分析、ブートストラップ信頼区間、順列検定
- すべてのコードは研究リポジトリで公開されています
Google-Algorithmus-Leak (Mai 2024)
Die in dieser Studie verwendeten Content-Quality-Signale – contentEffort, originalContentScore, page2vecLq – wurden aus geleakten internen Dokumenten der Google API identifiziert:
- King, M. (2024). "An Exploration of the Google Ranking Algorithm Leak." iPullRank. https://ipullrank.com/google-algo-leak
- Erste Analyse der versehentlich öffentlich gemachten Dokumente zum Google Content API Warehouse (2.596 Module, 14.014 Attribute).
- Anderson, S. (2024). "The contentEffort Attribute, The Helpful Content System and E-E-A-T — Is Gemini Behind the HCU?" Hobo Web. https://www.hobo-web.co.uk/the-contenteffort-attribute-the-helpful-content-system-and-e-e-a-t-is-gemini-behind-the-hcu/
- Detaillierte Analyse der Beziehung zwischen dem Attribut
contentEffortund dem Helpful-Content-System. - Fishkin, R. (2024). "An Anonymous Source Shared Thousands of Leaked Google Search API Documents with Me; Everyone in SEO Should See Them." SparkToro. https://sparktoro.com/blog/an-anonymous-source-shared-thousands-of-leaked-google-search-api-documents-with-me-everyone-in-seo-should-see-them/
- Unabhängige Veröffentlichung, die die Authentizität des Leaks bestätigte.
- Google (2024). Content API Warehouse-Dokumentation (Repository yoshi-code-bot/google-api-java-client-services, später gelöscht). Originalquelle, die die Definition des
googleapi.contentwarehouse-Moduls enthielt.
BM25 und gewichtete Feldsuche
- Robertson, S.E., Walker, S., Jones, S., Hancock-Beaulieu, M., & Gatford, M. (1995). "Okapi at TREC-3." In Proceedings of the Third Text REtrieval Conference (TREC-3). NIST.
- Grundlagenarbeit, die die BM25-Ranking-Funktion vorstellt, die für die Keyword-Relevanzanalyse dieser Studie verwendet wurde.
- Robertson, S.E., Zaragoza, H., & Taylor, M. (2004). "Simple BM25 Extension to Multiple Weighted Fields." In Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management (CIKM '04), pp. 42-49. https://doi.org/10.1145/1031171.1031181
- Stellt BM25F vor, eine feldgewichtete Erweiterung, die unterschiedliche Gewichte für Felder wie Titel, Haupttext und Ankertext ermöglicht. Es wird angenommen, dass die grundlegende Suchschicht von Google eine Variante dieser Technik verwendet.
- Robertson, S.E. & Zaragoza, H. (2009). "The Probabilistic Relevance Framework: BM25 and Beyond." Foundations and Trends in Information Retrieval, 3(4), pp. 333-389. https://doi.org/10.1561/1500000019
- Umfassende Untersuchung von BM25-Varianten, einschließlich BM25F, BM25+ und Näherungserweiterungen.
Google Passage Ranking
- Nayak, P. (2020). "How AI is powering a more helpful Google." Google Blog, 15. Oktober 2020. https://blog.google/products/search/search-on/
- Ankündigung des Passage-based Ranking. Ermöglicht es Google, einzelne Passagen innerhalb eines Dokuments zu bewerten, anstatt die gesamte Seite, was die Suchgenauigkeit bei langen Inhalten verbessert.
- Google Search Central (2021). "Passage Ranking launch." Februar 2021.
- Bestätigt das globale Rollout der passagenbasierten Indizierung. Verändert die Suchgrundlage, um für bestimmte Suchanfragen auf Passagen- statt auf Dokumentenebene zu bewerten.
Richtlinien für Qualitätsbewerter und E-E-A-T
- Google (2024). "Google Search Quality Evaluator Guidelines." Datiert März 2024. https://guidelines.raterhub.com/searchqualityevaluatorguidelines.pdf
- Offizielle Richtlinien, die von Googles menschlichen Qualitätsbewertern verwendet werden. Definieren die Kriterien für Expertise, Erfahrung, Autorität und Vertrauenswürdigkeit (E-E-A-T).
Tools und Datenquellen
-
rs-trafilatura
-
Rust-Portierung der Content-Extraction-Bibliothek trafilatura. Wird für die HTML-zu-Markdown-Konvertierung mit Entfernung von Boilerplate-Inhalt verwendet. F1-Score von 0,966 auf Article-Extraction-Benchmarks. 7-mal schneller als die Go-Implementierung.
-
Crawl4AI
-
Open-Source-Webcrawler und -Scraper mit LLM-Unterstützung. Wird für das Herunterladen von Seiten mit JavaScript-Unterstützung in der Wiederholungsphase via Playwright verwendet.
-
Serper API
-
Anbieter von Google-SERP-Daten. https://serper.dev
-
Wird verwendet, um die Top-30 organischen Suchergebnisse für jedes Keyword abzurufen.
-
DataForSEO Backlinks API
-
Domain-Autoritäts- und Backlink-Metriken. https://dataforseo.com
-
Wird verwendet, um den Domain-Rang (PageRank-Proxy, Skala 0-1000), die Anzahl der Backlinks und die Anzahl der verweisenden Domains zu erhalten.
-
MiMo-V2-Flash – 309B-Parameter (15B aktiv) Mixture-of-Experts-Modell von Xiaomi. Zugriff über OpenRouter. https://github.com/xiaomimimo/MiMo-V2-Flash
-
Wird für die groß angelegte Bewertung der Inhaltsqualität verwendet (Input 0,09 $/M Tokens, Output 0,29 $/M Tokens).
-
Claude Opus 4.6
-
Reasoning-Modell von Anthropic. Wird als Referenz für die Kalibrierung der LLM-Bewertung verwendet (Pilottest mit 150 Seiten).
Statistische Methoden
- Cohen, J. (1960). "A Coefficient of Agreement for Nominal Scales." Educational and Psychological Measurement, 20(1), pp. 37-46.
- Cohens Kappa, verwendet zur Berechnung der Interrater-Übereinstimmung bei der Validierung der LLM-Bewertung.
- Spearman, C. (1904). "The Proof and Measurement of Association between Two Things." The American Journal of Psychology, 15(1), pp. 72-101.
- Spearmans Rangkorrelation. Hauptstatistische Methode, die durchgehend in dieser Studie verwendet wird.
- Lundberg, S.M. & Lee, S.I. (2017). "A Unified Approach to Interpreting Model Predictions." In Advances in Neural Information Processing Systems 30 (NeurIPS 2017). https://arxiv.org/abs/1705.07874
- SHAP-Werte (SHapley Additive exPlanations). Werden für die Analyse der Merkmalswichtigkeit im Random-Forest-Modell verwendet.