La qualité du contenu prédit-elle réellement le classement Google ? J'ai analysé 44 000 pages pour le découvrir.

J'ai évalué 44 465 résultats SERP pour 2 212 mots-clés aux États-Unis à l'aide de grilles d'évaluation de la qualité du contenu basées sur des LLM, puis j'ai testé si ces scores prédisent les classements Google après avoir contrôlé l'autorité du domaine. Voici ce que j'ai découvert.
La question à laquelle personne ne peut répondre avec des données
L'industrie du SEO repose sur un postulat : créez un excellent contenu et vous serez bien classé. Les propres consignes de Google le disent. Mais lorsque vous demandez "à quel point la qualité du contenu compte-t-elle vraiment par rapport à l'autorité du domaine ?" — personne ne dispose des données.
J'ai décidé de le découvrir.
Ce que j'ai fait
J'ai construit un pipeline pour tester une hypothèse simple :
H1 : Après avoir contrôlé l'autorité du domaine, les scores de qualité du contenu sont corrélés négativement avec la position SERP (une qualité plus élevée → un meilleur classement).
L'ensemble de données
- 2 212 mots-clés américains issus d'Ahrefs (intention informationnelle + commerciale, non marqués)
- Les 30 premiers résultats pour chaque mot-clé via l'API Serper
- 60 409 résultats SERP explorés et extraits en markdown à l'aide de rs-trafilatura
- 44 465 pages évaluées après filtrage pour la qualité de l'extraction
- L'autorité de domaine pour 8 169 domaines uniques via l'API Backlinks de DataForSEO
L'évaluation
Avant d'évaluer quoi que ce soit à grande échelle, j'ai réalisé un test pilote sur 150 pages comparant MiMo-V2-Flash à Claude Opus 4.6. La concordance était forte (Spearman ρ = 0,766, κ de Cohen = 0,747), j'ai donc poursuivi. Chaque page a été évaluée sur trois dimensions :
| Grille | Basée sur | Ce qu'elle mesure |
|---|---|---|
| Effort de contenu | Le signal contentEffort divulgué de Google | Quel effort véritable a été consacré ? Un IA pourrait-elle le reproduire en quelques minutes ? |
| Originalité | Le signal originalContentScore divulgué de Google | Ajoute-t-il de nouvelles connaissances, ou se contente-t-il de réorganiser ce qui existe déjà ? |
| Cohérence thématique | Le signal page2vecLq de Google | Chaque section sert-elle le sujet central, ou la page s'égare-t-elle ? |
Chaque grille était notée de 1 à 5 avec des règles d'étalonnage, des exemples concrets et des pièges à faux positifs que j'ai affinés au fil de plusieurs projets clients. Ce sont les grilles, et non le modèle, qui font le gros du travail — les invites d'évaluation sont suffisamment détaillées pour que tout LLM compétent produise des résultats similaires, c'est pourquoi le pilote a montré une forte concordance entre deux modèles très différents. J'ai publié les grilles complètes avec des exemples concrets séparément si vous souhaitez évaluer votre propre contenu.
Une note sur la signification statistique
Avec 44 000 observations, la signification statistique est triviale à atteindre — même des effets minuscules et sans signification montrent un p < 0,001. Je me concentre donc sur l'ampleur de l'effet, la signification pratique, et le fait que les résultats tiennent avec plusieurs méthodes plutôt que sur les valeurs p. Si l'effet n'est pas assez grand pour avoir de l'importance en pratique, peu m'importe qu'il soit "statistiquement significatif".
Les méthodes
Je ne me suis pas fié à un seul test. J'ai utilisé 8 méthodes indépendantes pour faire une triangulation. Les méthodes 3 et 5 traitent correctement la structure imbriquée (plusieurs pages en concurrence pour le même mot-clé ne sont pas indépendantes) ; les autres non, donc leurs valeurs p s'accompagnent de cette réserve :
- Corrélation de rang de Spearman
- Spearman partielle (contrôlant l'autorité du domaine)
- Analyse de rang intra-mot-clé (comparant les pages en concurrence pour la même requête)
- Test de permutation (1 000 mélanges pour des valeurs p de référence)
- Modèle linéaire à effets mixtes (gère l'imbrication)
- Moindres carrés ordinaires (MCO) avec erreurs types groupées
- Régression logistique pour la probabilité top-10
- Forêt aléatoire avec importance des caractéristiques SHAP
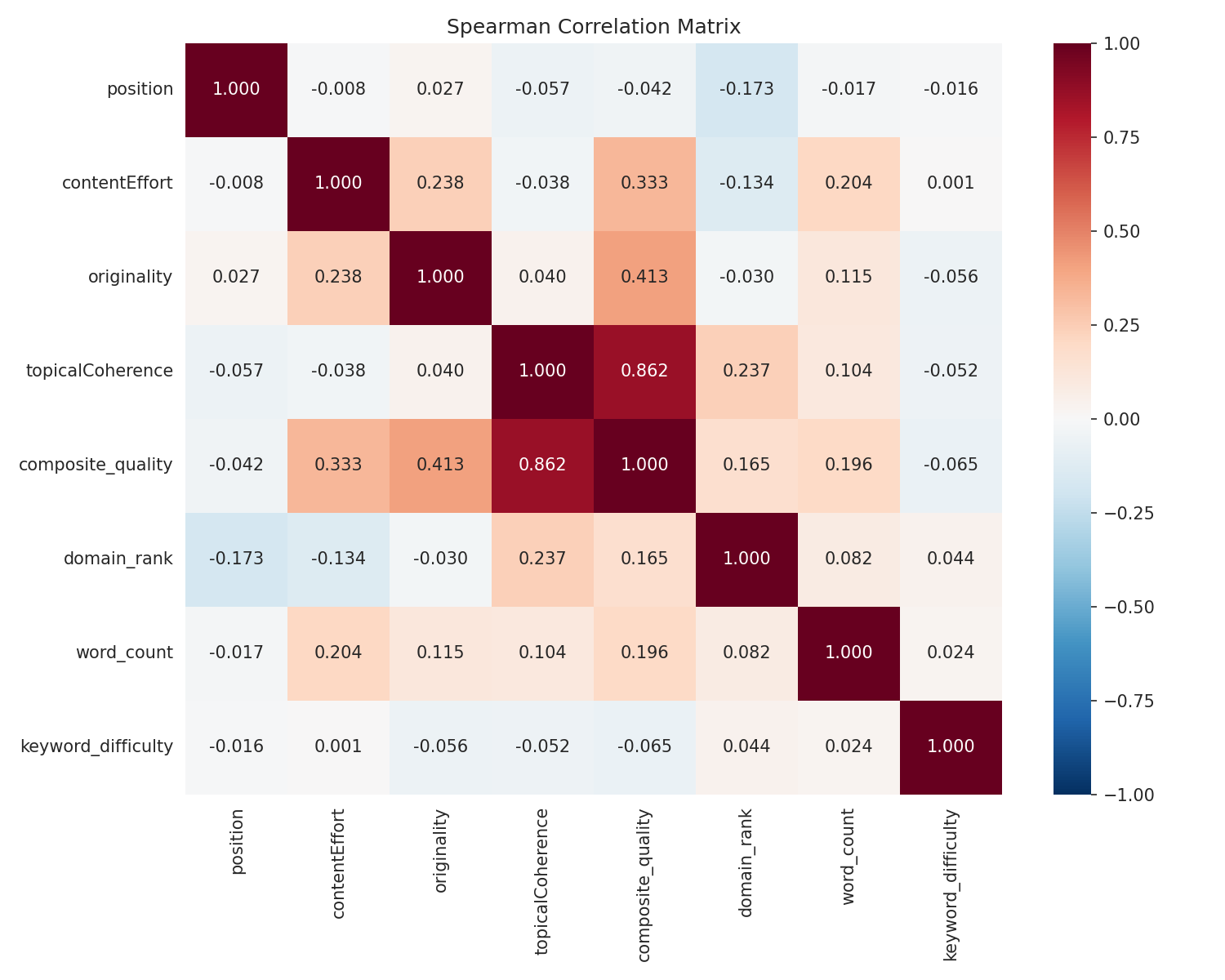
Les résultats
Oui, la qualité du contenu prédit les classements — mais dans quelle mesure ?
Les 8 méthodes pointent dans la même direction. La qualité du contenu est associée à de meilleurs classements, même après avoir contrôlé l'autorité du domaine.
Mais c'est l'ampleur de l'effet qui compte ici, pas les valeurs p.
L'autorité de domaine est 10 fois plus importante
La forêt aléatoire (entraînée sur 35 621 pages, validée sur 8 844 pages retenues, R² = 0,178) le montre clairement :
| Caractéristique | Importance |
|---|---|
| Autorité de domaine | 49,7 % |
| Nombre de mots | 31,6 % |
| Difficulté du mot-clé | 11,8 % |
| Cohérence thématique | 3,7 % |
| Effort de contenu | 1,7 % |
| Originalité | 1,5 % |
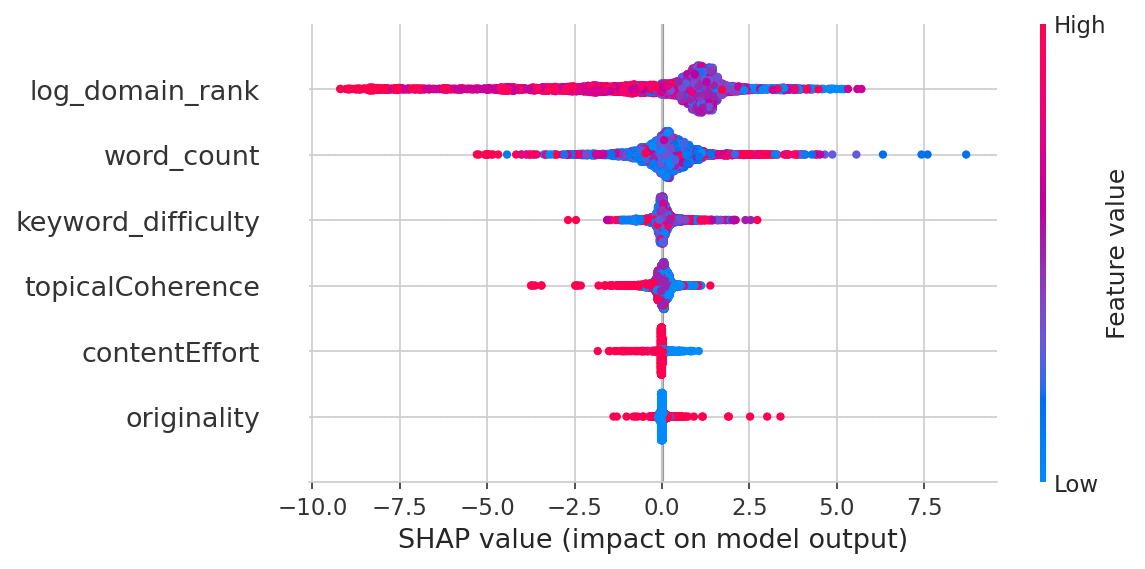
L'autorité de domaine à elle seule explique la moitié de la variation des classements. La qualité du contenu contribue collectivement à environ 7 %. Et le modèle complet n'explique que 18 % de ce qui se passe — les autres 82 % sont des facteurs que je n'ai pas mesurés (backlinks au niveau de la page, engagement des utilisateurs, Core Web Vitals, signaux de marque, etc.). Pour contexte, les études publiées sur les facteurs de classement SEO rapportent généralement des valeurs R² de 0,10-0,25. Aucun modèle n'explique la plupart des décisions de classement de Google — si c'était le cas, nous serions tous à la retraite.
Mais ces 7 % sont réels et constants
À travers les 8 méthodes, le signal se maintient :
| Méthode | Constatation | valeur p |
|---|---|---|
| Spearman (brute) | Cohérence thématique : ρ = -0,057 | p < 0,001 |
| Spearman partielle (contrôle DA) | Toujours présent : ρ = -0,017 | p < 0,001 |
| Analyse intra-mot-clé | Médiane ρ = -0,066, la qualité prédit le rang pour 60,5 % des mots-clés | IC Bootstrap : [-0,080, -0,051] |
| Test de permutation | 11 écarts types par rapport à l'hypothèse nulle | p < 0,001 |
| Modèle à effets mixtes | -0,23 position par point de cohérence | p < 0,001 |
| MCO groupées | -0,51 position par point composite | p < 0,001 |
| Logistique (top-10) | +4,7 % de probabilité par point de cohérence | p < 0,001 |
Le test de permutation — qui ne fait aucune hypothèse de distribution et traite correctement l'imbrication — met cela hors de doute.
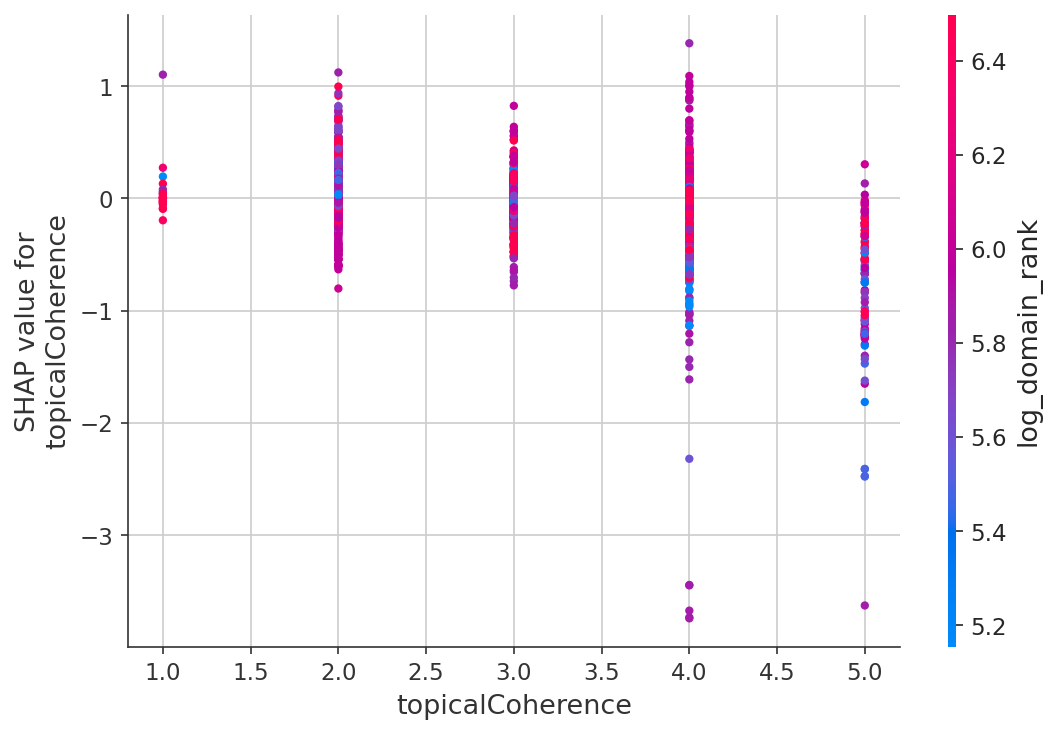
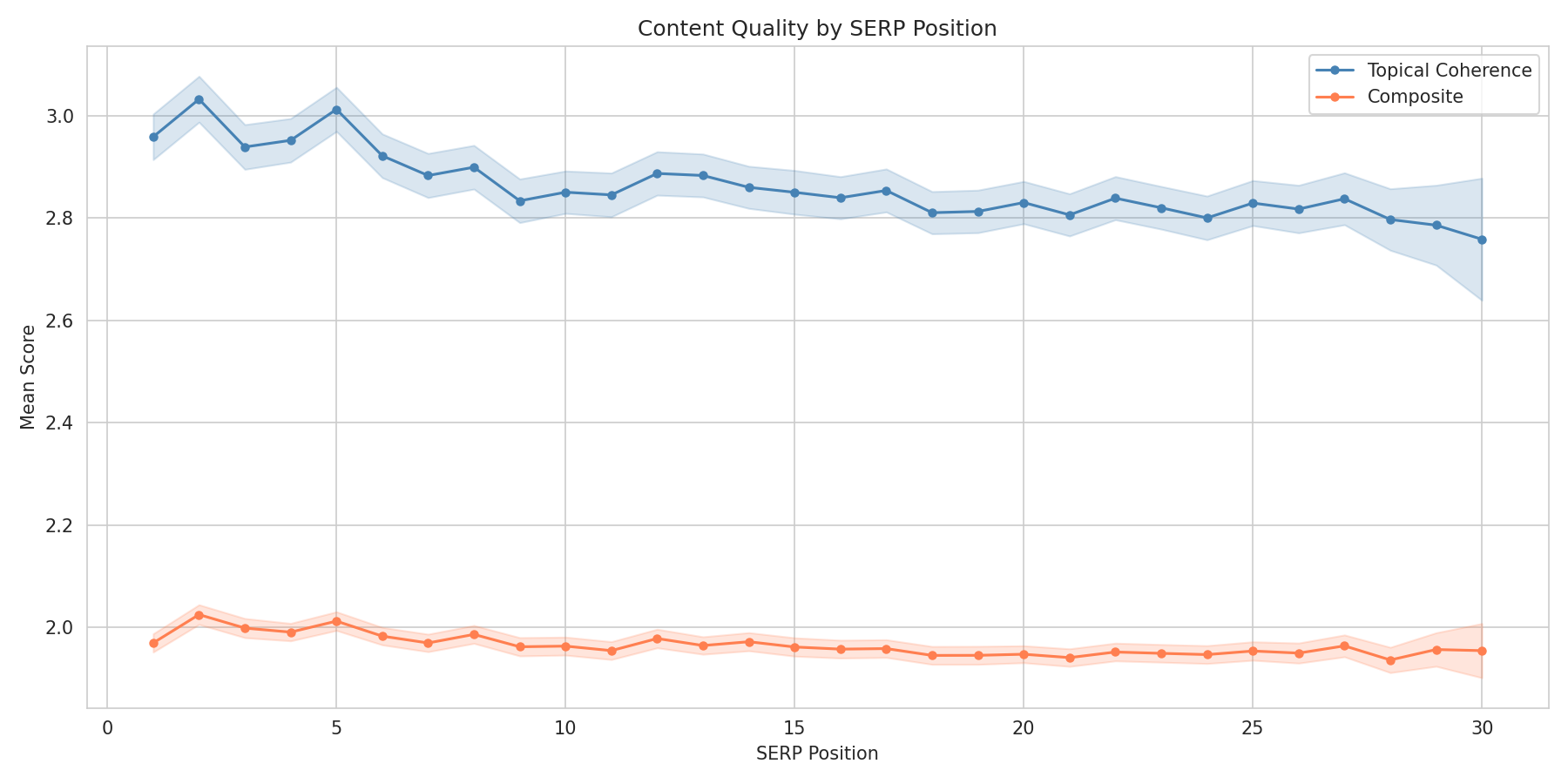
L'effet de cohérence thématique
Parmi les trois dimensions, la cohérence thématique a montré le lien le plus clair avec le classement. Les pages qui restent sur le sujet se classent mieux que celles qui essaient de tout couvrir.
| Score de cohérence thématique | Position moyenne | Taux Top-10 |
|---|---|---|
| 1 (Incohérente) | 15,27 | 32,0 % |
| 2 (Peu focalisée) | 14,53 | 34,9 % |
| 3 (Adéquate) | 14,27 | 36,1 % |
| 4 (Bien focalisée) | 13,52 | 40,2 % |
| 5 (Très focalisée) | 12,27 | 47,2 % |
Une page notée 5 en cohérence thématique a un taux top-10 de 47,2 % contre 32,0 % pour un score 1 — un écart de 15 points de pourcentage. Attention : N=980 pour le score 5 et N=338 pour le score 1, donc ces estimations extrêmes ont des intervalles de confiance plus larges que les scores intermédiaires.
Les nuances qui comptent
La qualité du contenu compte le plus quand on n'a pas d'autorité
C'était la découverte la plus intéressante. J'ai divisé les données par quartiles d'autorité de domaine :
| Autorité de domaine | Cohérence → Position ρ | Significatif ? |
|---|---|---|
| Q1 (autorité la plus faible) | ρ = -0,059 | Oui (p < 0,001) |
| Q2 | ρ = -0,035 | Oui (p < 0,001) |
| Q3 | ρ = +0,018 | Non |
| Q4 (autorité la plus élevée) | ρ = +0,011 | Non |
![]()
Pour les domaines à faible autorité, la qualité du contenu est un véritable facteur de différenciation. Pour les domaines à haute autorité, cela importe à peine — ils se classent quoi qu'il arrive.
En clair : Si vous êtes Forbes, vous pouvez publier un contenu médiocre et toujours bien vous classer. Si vous êtes une startup, la qualité du contenu est l'un des rares leviers que vous avez réellement.
Ce que je ferais avec un budget plus important : J'ai utilisé l'autorité au niveau du domaine car les données de backlinks au niveau de la page pour 44 000 URL dépassaient mon budget (j'y reviendrai peut-être à l'avenir). L'autorité de domaine est un instrument grossier — elle indique que le site est fort, mais pas si cette page spécifique a gagné des liens. Avec des comptes de domaines référents au niveau de la page, je pourrais tester si un contenu à fort effort attire plus de backlinks au niveau de la page, et si l'effet qualité → classement passe par l'acquisition de liens plutôt que par un signal direct. C'est quelque chose que je veux examiner ensuite.
Les mots-clés informationnels sont là où le contenu importe
J'ai testé si l'effet diffère selon l'intention de recherche :
| Intention | ρ intra-mot-clé | % de mots-clés montrant l'effet |
|---|---|---|
| Uniquement informationnel | -0,101 | 65 % |
| Commercial + Informationnel | -0,041 | 56 % |
La différence est claire (test z de Fisher, p < 0,001). La qualité du contenu importe 2,5 fois plus pour les requêtes informationnelles que commerciales.
Les mots-clés faciles récompensent davantage la qualité
| Difficulté du mot-clé | ρ intra-mot-clé | % Négatif |
|---|---|---|
| KD 0-20 (facile) | -0,080 | 63 % |
| KD 21-40 | -0,081 | 64 % |
| KD 41-60 | -0,048 | 56 % |
| KD 61+ (difficile) | -0,007 | 51 % |
Pour les mots-clés compétitifs, l'autorité domine si complètement que la qualité du contenu n'a presque aucun effet. Pour les mots-clés peu concurrentiels, la qualité compte réellement.
Ce qui ne fonctionne pas : le bourrage de mots-clés
Une mise en garde ici est que le BM25 de Google, que nous supposons être la porte d'entrée de pertinence pour être inclus dans l'index principal pour un terme de recherche, a évolué au fil des ans. Alors que j'exécutais les scores BM25 standards (pertinence/densité des mots-clés), j'ai trouvé quelque chose d'inattendu :
| Bande de position | Score BM25 moyen |
|---|---|
| Top 1-5 | 3,950 |
| 6-10 | 3,967 |
| 11-20 | 4,016 |
| 21-30 | 4,056 |
Les pages mieux classées ont une densité de mots-clés légèrement inférieure. L'analyse intra-mot-clé l'a confirmé : BM25 est corrélé positivement avec la position (ρ = +0,045), ce qui signifie que les pages plus bourrées de mots-clés se classent moins bien.
C'est logique quand on y pense. Les pages les mieux classées sont généralement des domaines autoritaires qui traitent les sujets naturellement. Les pages moins bien classées sont souvent des pages de service sur-optimisées qui martèlent le mot-clé.
---## Ce que cela signifie pour la stratégie de contenu
Pour de nombreux référenceurs, c'est un peu un
"donc vous dites que l'eau est mouillée"
moment, et vous auriez raison.
Si vous avez une autorité de domaine faible (< Médiane)
- La qualité du contenu est l'un de vos meilleurs leviers. Un article bien ciblé et cohérent a une chance mesurablement meilleure de se classer qu'un contenu éparpillé et peu ciblé.
- La cohérence thématique est primordiale. Choisissez UN seul sujet par page et traitez-le correctement. N'essayez pas de vous classer pour cinq mots-clés avec un seul "guide ultime".
- Ciblez des mots-clés informationnels à faible KD (Keyword Difficulty). C'est là que la qualité du contenu a l'effet le plus fort.
Si vous avez une autorité de domaine élevée
- La qualité du contenu offre des rendements décroissants. Votre autorité vous permet déjà d'être bien classé. Polir le contenu a un effet marginal faible.
- Concentrez-vous sur le maintien de l'autorité — les backlinks, la marque, les signaux de confiance comptent plus que la réécriture d'articles.
Pour tout le monde
- Arrêtez le bourrage de mots-clés. C'est légèrement contre-productif.
- La focalisation bat l'effort. Une page focalisée et cohérente surclasse une page longue et éparpillée — même si cette dernière a demandé plus de travail à produire.
Qu'en est-il de l'effort de contenu ?
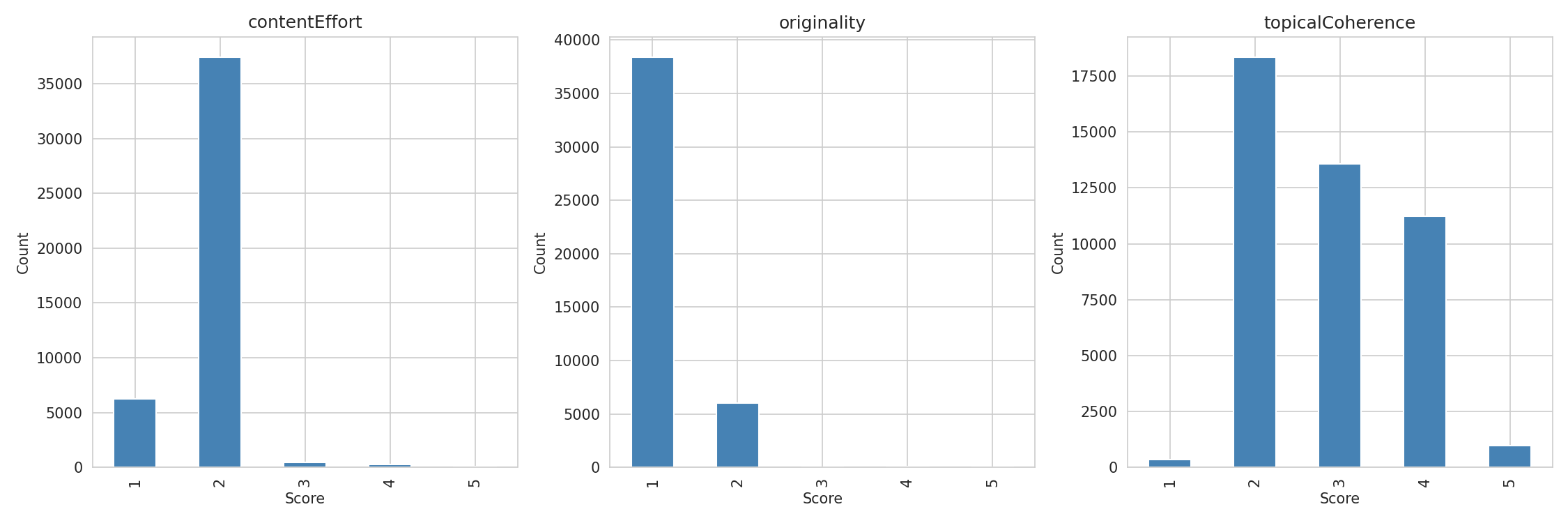
Celui-ci mérite sa propre discussion. Je n'ai trouvé aucune corrélation significative entre les scores d'effort de contenu et le classement dans la plage normale (scores 1-2). Mais 84 % des pages ont obtenu un score de 2 et 14 % un score de 1 — je comparais essentiellement un "effort faible" à un "effort très faible". Seulement 1,8 % des pages dans le top 30 contenaient des données propriétaires, des recherches originales ou une expertise documentée.
Ce n'est pas vraiment une découverte sur l'importance de l'effort. C'est une découverte sur la rareté d'un véritable effort. Le contenu à fort effort est si peu courant dans les résultats de recherche que je n'en avais tout simplement pas assez pour mesurer son effet.
Mon hypothèse de travail — que ces données ne peuvent pas prouver mais ne contredisent pas — est que l'effet de classement de l'effort est blanchi à travers les backlinks. Le contenu à fort effort (données originales, interviews d'experts, recherches propriétaires) est citable. Le contenu citable attire des liens. Les liens construisent l'autorité de domaine. Et l'autorité de domaine est le facteur de classement dominant. Ainsi, l'effort pourrait compter énormément, mais son effet apparaît dans la métrique d'autorité plutôt que comme un signal de qualité indépendant.
Si j'avais (quand j'aurai) des données de backlinks au niveau page (plutôt qu'au niveau domaine), je pourrais tester si les pages à fort effort attirent plus de domaines référents. C'est la prochaine étude. Je présume qu'ils sont fortement corrélés.
Originalité : Le Web est dérivatif
86 % des pages classées dans le top 30 ont obtenu un score de 1 sur l'originalité — entièrement dérivatives. Ce n'est pas un bug dans le système de notation. Essayez vous-même le Test Google : recherchez n'importe quelle requête informationnelle, lisez les 10 premiers résultats, et comptez combien contiennent une seule affirmation que vous ne trouvez pas dans les 9 autres. Presque aucune.
Le seuil pour une originalité "au-dessus de la moyenne" est étonnamment bas. Google ne semble pas pénaliser lourdement le contenu dérivatif — ou si c'est le cas, la pénalité est déjà intégrée dans le signal d'autorité (contenu original → citations → liens → autorité).
Mon avis est qu'à mesure que les LLMs prendront en charge de plus en plus les responsabilités de rédaction de contenu, les nouvelles données uniques associées à une démonstration d'analyse issue de l'expérience seront davantage un facteur décisif, mais la question est de savoir comment Google, etc., peut mesurer cela à grande échelle ?
Limites
Cette étude présente de réelles limites dont il convient d'être transparent :
- La notation par LLM est un proxy. C'est MiMo-V2-Flash qui a noté ces pages, pas les évaluateurs de qualité de Google. Les scores LLM sont des estimations bruyantes, bien que la validation pilote (ρ = 0,766, κ = 0,747 par rapport au référentiel Opus) suggère qu'ils sont raisonnablement cohérents.
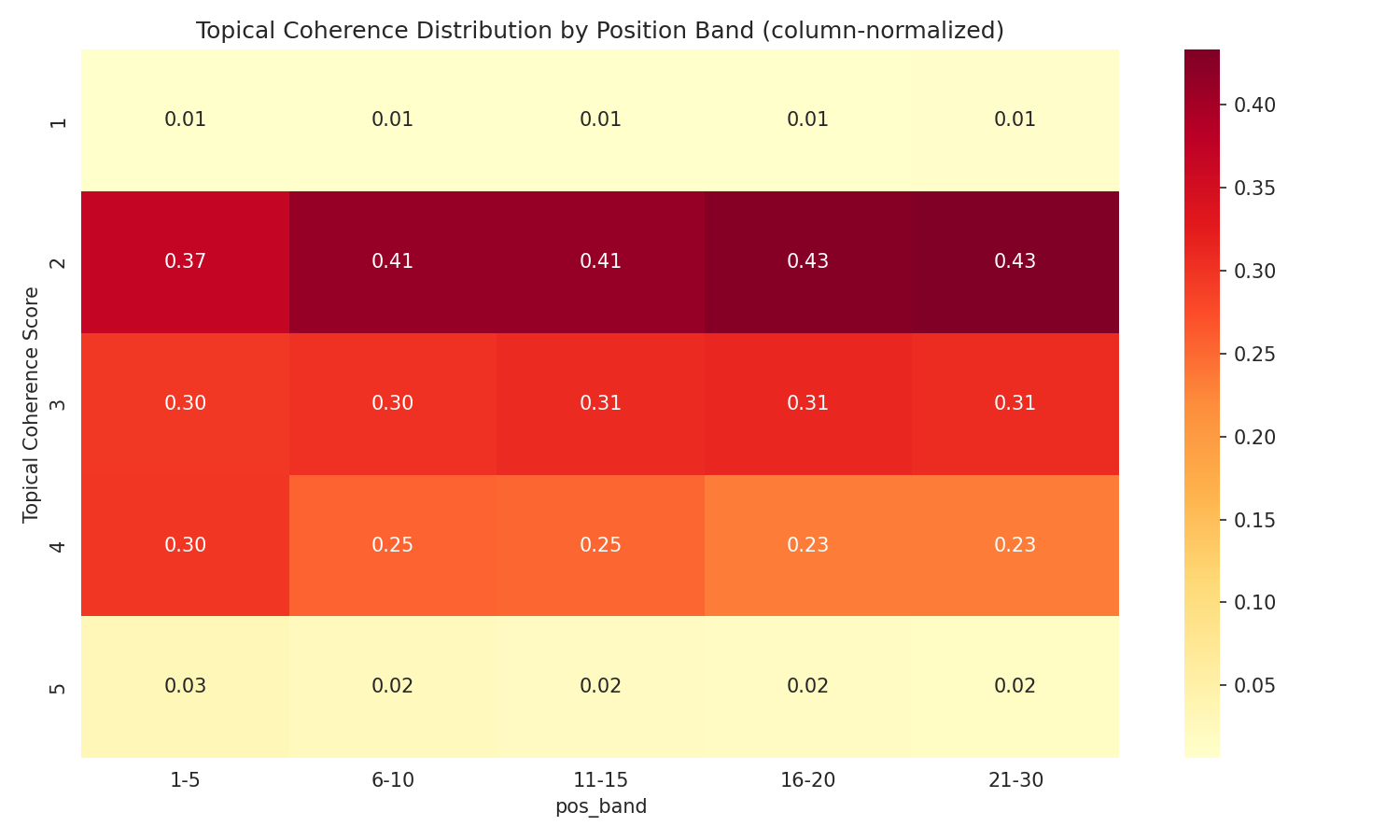
- Distributions de scores comprimées. 84 % des pages ont obtenu un score de 2 sur l'Effort de Contenu et 86 % un score de 1 sur l'Originalité. Ce n'est pas une faute de notation — c'est un reflet fidèle du web. Presque aucun contenu bien classé ne contient de données propriétaires ou de recherches originales. Mais cela limite la puissance statistique pour ces critères. La Cohérence Thématique avait la distribution la plus large (41 % score 2, 30 % score 3, 25 % score 4) et a montré le signal le plus fort — en partie parce que c'est la dimension où les pages diffèrent réellement les unes des autres.
- Conception transversale. J'ai mesuré les classements et la qualité à un moment donné. Je ne peux pas prouver qu'améliorer la qualité du contenu provoque des améliorations de classement — seulement que qualité et classement sont associés.
- Facteurs confusionnels non mesurés. J'ai contrôlé l'autorité de domaine, le nombre de mots et la difficulté du mot-clé, mais de nombreux facteurs de classement n'ont pas été mesurés : vélocité des backlinks, engagement des utilisateurs, Core Web Vitals, vitesse de la page, recherches de marque, etc. L'autorité de domaine et le nombre de mots sont également probablement corrélés (les sites à haute autorité produisent des contenus plus longs), donc l'importance de 31,6 % de la fonctionnalité "nombre de mots" peut en partie servir de proxy pour l'autorité.
- Qualité de l'extraction de contenu. rs-trafilatura gère bien les articles (F1 0,93) mais peut mal extraire les pages produits ou les SPAs, ajoutant du bruit pour certains types de pages.
- BM25 Vanilla. J'ai utilisé l'Okapi BM25 de base sans pondération de champ, score de proximité ou score au niveau des passages. Une implémentation BM25F alignée sur les brevets de Google montrerait probablement des résultats différents.
- Comparaisons multiples. J'ai effectué plus de 50 tests à travers les méthodes, critères et sous-groupes. Certaines découvertes marginales pourraient ne pas survivre à la correction de Bonferroni. Les découvertes principales — effet de cohérence thématique, interaction par quartile d'AD, différence d'intention — résistent à travers plusieurs méthodes indépendantes avec des tailles d'effet cohérentes.
Détails méthodologiques
Collecte de données
- Mots-clés : 2 212 mots-clés US d'Ahrefs, filtrés pour intention Informationnelle + Commerciale, requêtes non marquées dans le vertical développement logiciel
- Données SERP : API Serper (3 pages de 10 par mot-clé = top 30 résultats)
- Téléchargement HTML : httpx concurrent (94%), fallback Playwright pour pages rendues en JS (4%)
- Extraction de contenu : rs-trafilatura (Rust, précision F1 0,966)
- Autorité de domaine : API DataForSEO Backlinks Summary (rank au niveau domaine, échelle 0-1000)
Notation
- Modèle : Xiaomi MiMo-V2-Flash (309B MoE, 15B paramètres actifs) via OpenRouter
- 3 critères × 44 465 pages = 133 395 appels API
- Coût total de notation LLM : ~87$
Analyse statistique
- 8 méthodes indépendantes avec des résultats cohérents
- Méthode principale : analyse des rangs de Spearman intra-mot-clé avec intervalle de confiance bootstrap et test de permutation
- Tout le code disponible dans le dépôt de recherche
Google-Algorithmus-Leak (Mai 2024)
Die in dieser Studie verwendeten Content-Quality-Signale – contentEffort, originalContentScore, page2vecLq – wurden aus geleakten internen Dokumenten der Google API identifiziert:
- King, M. (2024). "An Exploration of the Google Ranking Algorithm Leak." iPullRank. https://ipullrank.com/google-algo-leak
- Erste Analyse der versehentlich öffentlich gemachten Dokumente zum Google Content API Warehouse (2.596 Module, 14.014 Attribute).
- Anderson, S. (2024). "The contentEffort Attribute, The Helpful Content System and E-E-A-T — Is Gemini Behind the HCU?" Hobo Web. https://www.hobo-web.co.uk/the-contenteffort-attribute-the-helpful-content-system-and-e-e-a-t-is-gemini-behind-the-hcu/
- Detaillierte Analyse der Beziehung zwischen dem Attribut
contentEffortund dem Helpful-Content-System. - Fishkin, R. (2024). "An Anonymous Source Shared Thousands of Leaked Google Search API Documents with Me; Everyone in SEO Should See Them." SparkToro. https://sparktoro.com/blog/an-anonymous-source-shared-thousands-of-leaked-google-search-api-documents-with-me-everyone-in-seo-should-see-them/
- Unabhängige Veröffentlichung, die die Authentizität des Leaks bestätigte.
- Google (2024). Content API Warehouse-Dokumentation (Repository yoshi-code-bot/google-api-java-client-services, später gelöscht). Originalquelle, die die Definition des
googleapi.contentwarehouse-Moduls enthielt.
BM25 und gewichtete Feldsuche
- Robertson, S.E., Walker, S., Jones, S., Hancock-Beaulieu, M., & Gatford, M. (1995). "Okapi at TREC-3." In Proceedings of the Third Text REtrieval Conference (TREC-3). NIST.
- Grundlagenarbeit, die die BM25-Ranking-Funktion vorstellt, die für die Keyword-Relevanzanalyse dieser Studie verwendet wurde.
- Robertson, S.E., Zaragoza, H., & Taylor, M. (2004). "Simple BM25 Extension to Multiple Weighted Fields." In Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management (CIKM '04), pp. 42-49. https://doi.org/10.1145/1031171.1031181
- Stellt BM25F vor, eine feldgewichtete Erweiterung, die unterschiedliche Gewichte für Felder wie Titel, Haupttext und Ankertext ermöglicht. Es wird angenommen, dass die grundlegende Suchschicht von Google eine Variante dieser Technik verwendet.
- Robertson, S.E. & Zaragoza, H. (2009). "The Probabilistic Relevance Framework: BM25 and Beyond." Foundations and Trends in Information Retrieval, 3(4), pp. 333-389. https://doi.org/10.1561/1500000019
- Umfassende Untersuchung von BM25-Varianten, einschließlich BM25F, BM25+ und Näherungserweiterungen.
Google Passage Ranking
- Nayak, P. (2020). "How AI is powering a more helpful Google." Google Blog, 15. Oktober 2020. https://blog.google/products/search/search-on/
- Ankündigung des Passage-based Ranking. Ermöglicht es Google, einzelne Passagen innerhalb eines Dokuments zu bewerten, anstatt die gesamte Seite, was die Suchgenauigkeit bei langen Inhalten verbessert.
- Google Search Central (2021). "Passage Ranking launch." Februar 2021.
- Bestätigt das globale Rollout der passagenbasierten Indizierung. Verändert die Suchgrundlage, um für bestimmte Suchanfragen auf Passagen- statt auf Dokumentenebene zu bewerten.
Richtlinien für Qualitätsbewerter und E-E-A-T
- Google (2024). "Google Search Quality Evaluator Guidelines." Datiert März 2024. https://guidelines.raterhub.com/searchqualityevaluatorguidelines.pdf
- Offizielle Richtlinien, die von Googles menschlichen Qualitätsbewertern verwendet werden. Definieren die Kriterien für Expertise, Erfahrung, Autorität und Vertrauenswürdigkeit (E-E-A-T).
Tools und Datenquellen
-
rs-trafilatura
-
Rust-Portierung der Content-Extraction-Bibliothek trafilatura. Wird für die HTML-zu-Markdown-Konvertierung mit Entfernung von Boilerplate-Inhalt verwendet. F1-Score von 0,966 auf Article-Extraction-Benchmarks. 7-mal schneller als die Go-Implementierung.
-
Crawl4AI
-
Open-Source-Webcrawler und -Scraper mit LLM-Unterstützung. Wird für das Herunterladen von Seiten mit JavaScript-Unterstützung in der Wiederholungsphase via Playwright verwendet.
-
Serper API
-
Anbieter von Google-SERP-Daten. https://serper.dev
-
Wird verwendet, um die Top-30 organischen Suchergebnisse für jedes Keyword abzurufen.
-
DataForSEO Backlinks API
-
Domain-Autoritäts- und Backlink-Metriken. https://dataforseo.com
-
Wird verwendet, um den Domain-Rang (PageRank-Proxy, Skala 0-1000), die Anzahl der Backlinks und die Anzahl der verweisenden Domains zu erhalten.
-
MiMo-V2-Flash – 309B-Parameter (15B aktiv) Mixture-of-Experts-Modell von Xiaomi. Zugriff über OpenRouter. https://github.com/xiaomimimo/MiMo-V2-Flash
-
Wird für die groß angelegte Bewertung der Inhaltsqualität verwendet (Input 0,09 $/M Tokens, Output 0,29 $/M Tokens).
-
Claude Opus 4.6
-
Reasoning-Modell von Anthropic. Wird als Referenz für die Kalibrierung der LLM-Bewertung verwendet (Pilottest mit 150 Seiten).
Statistische Methoden
- Cohen, J. (1960). "A Coefficient of Agreement for Nominal Scales." Educational and Psychological Measurement, 20(1), pp. 37-46.
- Cohens Kappa, verwendet zur Berechnung der Interrater-Übereinstimmung bei der Validierung der LLM-Bewertung.
- Spearman, C. (1904). "The Proof and Measurement of Association between Two Things." The American Journal of Psychology, 15(1), pp. 72-101.
- Spearmans Rangkorrelation. Hauptstatistische Methode, die durchgehend in dieser Studie verwendet wird.
- Lundberg, S.M. & Lee, S.I. (2017). "A Unified Approach to Interpreting Model Predictions." In Advances in Neural Information Processing Systems 30 (NeurIPS 2017). https://arxiv.org/abs/1705.07874
- SHAP-Werte (SHapley Additive exPlanations). Werden für die Analyse der Merkmalswichtigkeit im Random-Forest-Modell verwendet.