¿Realmente la calidad del contenido predice los rankings de Google? Analicé 44,000 páginas para descubrirlo.

Analicé 44.465 resultados de SERP en 2.212 palabras clave de EE. UU. utilizando rúbricas de calidad de contenido basadas en LLM, y luego probé si esas puntuaciones predicen el posicionamiento en Google después de controlar por la autoridad de dominio. Esto es lo que encontré.
La pregunta que nadie puede responder con datos
La industria del SEO funciona bajo un artículo de fe: crea contenido excelente y posicionarás. Las propias directrices de Google lo dicen. Pero cuando preguntas "¿cuánto importa realmente la calidad del contenido en comparación con la autoridad de dominio?" — nadie tiene los datos.
Decidí averiguarlo.
Qué hice
Creé un proceso para probar una hipótesis sencilla:
H1: Después de controlar por la autoridad de dominio, las puntuaciones de calidad del contenido están negativamente correlacionadas con la posición en el SERP (mayor calidad → mejor posicionamiento).
El conjunto de datos
- 2.212 palabras clave de EE. UU. de Ahrefs (intención informativa + comercial, no de marca)
- Los 30 primeros resultados para cada palabra clave a través de la API Serper
- 60.409 resultados de SERP rastreados y extraídos a markdown usando rs-trafilatura
- 44.465 páginas puntuadas después de filtrar por calidad de extracción
- Autoridad de dominio para 8.169 dominios únicos vía la API de Backlinks de DataForSEO
La puntuación
Antes de puntuar nada a escala, ejecuté una prueba piloto de 150 páginas comparando MiMo-V2-Flash con Claude Opus 4.6. La concordancia fue fuerte (Spearman ρ = 0.766, Cohen's κ = 0.747), así que seguí adelante. Cada página se puntuó en tres dimensiones:
| Rúbrica | Basada en | Lo que mide |
|---|---|---|
| Esfuerzo del Contenido | La señal filtrada contentEffort de Google | ¿Cuánto esfuerzo genuino se invirtió en esto? ¿Podría una IA replicarlo en minutos? |
| Originalidad | La señal filtrada originalContentScore de Google | ¿Aporta nuevo conocimiento, o solo reorganiza lo que ya existe? |
| Coherencia Temática | La señal page2vecLq de Google | ¿Cada sección sirve al tema principal, o la página divaga? |
Cada rúbrica se puntuó del 1 al 5 con reglas de calibración, ejemplos prácticos y trampas para falsos positivos que he refinado a lo largo de varios proyectos para clientes. Las rúbricas, no el modelo, hacen el trabajo pesado — los prompts de puntuación son lo suficientemente detallados como para que cualquier LLM competente produzca resultados similares, por eso la prueba piloto mostró una fuerte concordancia entre dos modelos muy diferentes. He publicado las rúbricas completas con ejemplos prácticos por separado si quieres puntuar tu propio contenido.
Una nota sobre la significancia estadística
Con 44.000 observaciones, alcanzar significancia estadística es trivialmente fácil — incluso efectos minúsculos y sin sentido muestran p < 0.001. Por eso me centro en los tamaños del efecto, la significancia práctica y si los hallazgos se mantienen en múltiples métodos, más que en los valores p. Si el efecto no es lo suficientemente grande como para importar en la práctica, no me importa que sea "estadísticamente significativo".
Los métodos
No confié en una sola prueba. Usé 8 métodos independientes para triangular. Los métodos 3 y 5 manejan adecuadamente la estructura anidada (las múltiples páginas que compiten por la misma palabra clave no son independientes); los otros no, así que sus valores p vienen con esa advertencia:
- Correlación de rangos de Spearman
- Spearman parcial (controlando por autoridad de dominio)
- Análisis de rango intra-palabra clave (comparando páginas que compiten por la misma consulta)
- Prueba de permutación (1.000 mezclas para valores p de referencia)
- Modelo lineal de efectos mixtos (maneja el anidamiento)
- Mínimos cuadrados ordinarios (OLS) con errores estándar agrupados
- Regresión logística para la probabilidad de estar en el top-10
- Bosque aleatorio con importancia de características SHAP
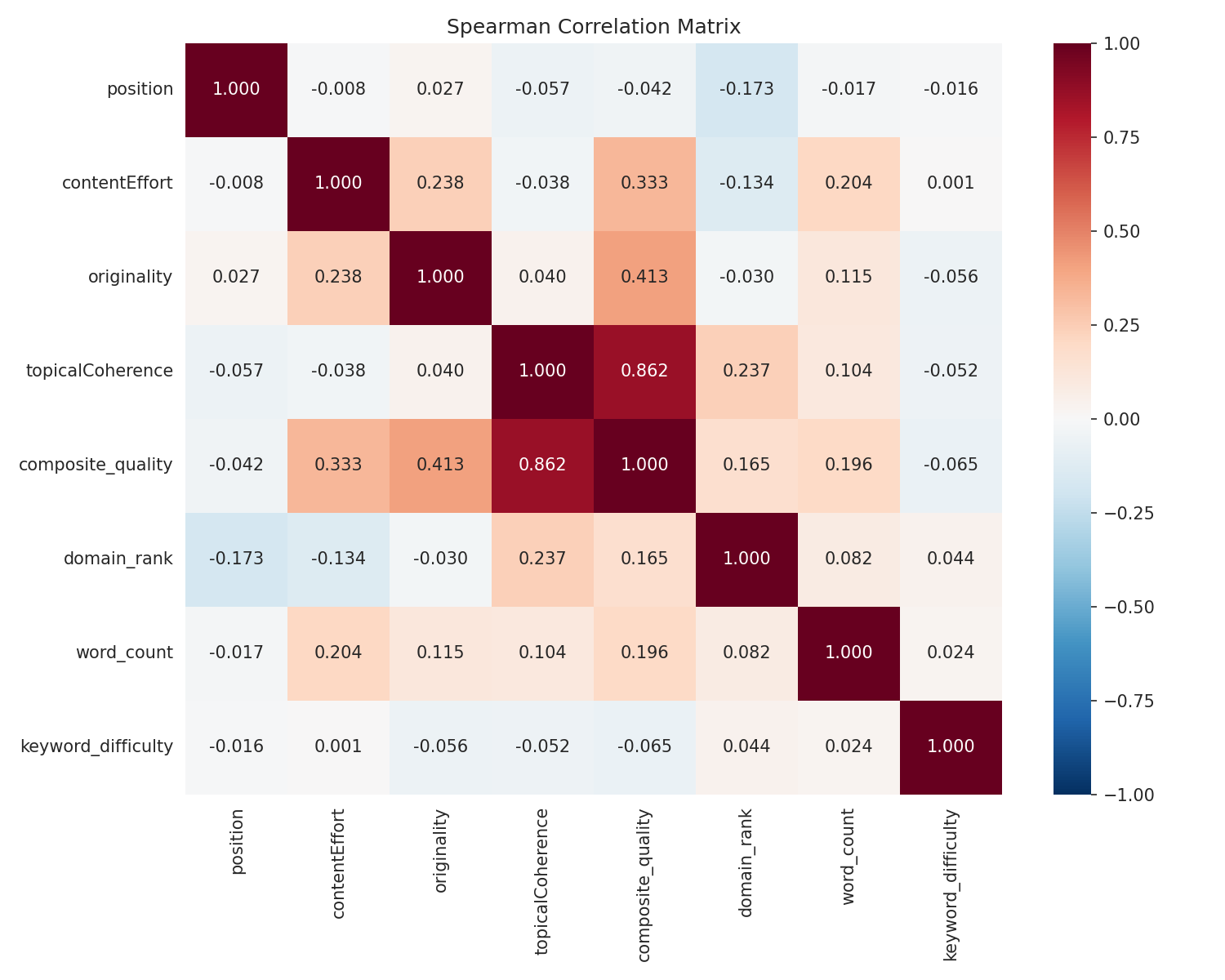
Los resultados
Sí, la calidad del contenido predice el posicionamiento — ¿Pero cuánto?
Los 8 métodos apuntaron en la misma dirección. La calidad del contenido está asociada con mejores posiciones, incluso después de controlar por la autoridad de dominio.
Pero el tamaño del efecto es lo que importa aquí, no los valores p.
La autoridad de dominio es 10 veces más importante
El bosque aleatorio (entrenado en 35.621 páginas, validado en 8.844 páginas reservadas, R² = 0.178) lo deja claro:
| Característica | Importancia |
|---|---|
| Autoridad de Dominio | 49,7% |
| Cantidad de Palabras | 31,6% |
| Dificultad de la Palabra Clave | 11,8% |
| Coherencia Temática | 3,7% |
| Esfuerzo del Contenido | 1,7% |
| Originalidad | 1,5% |
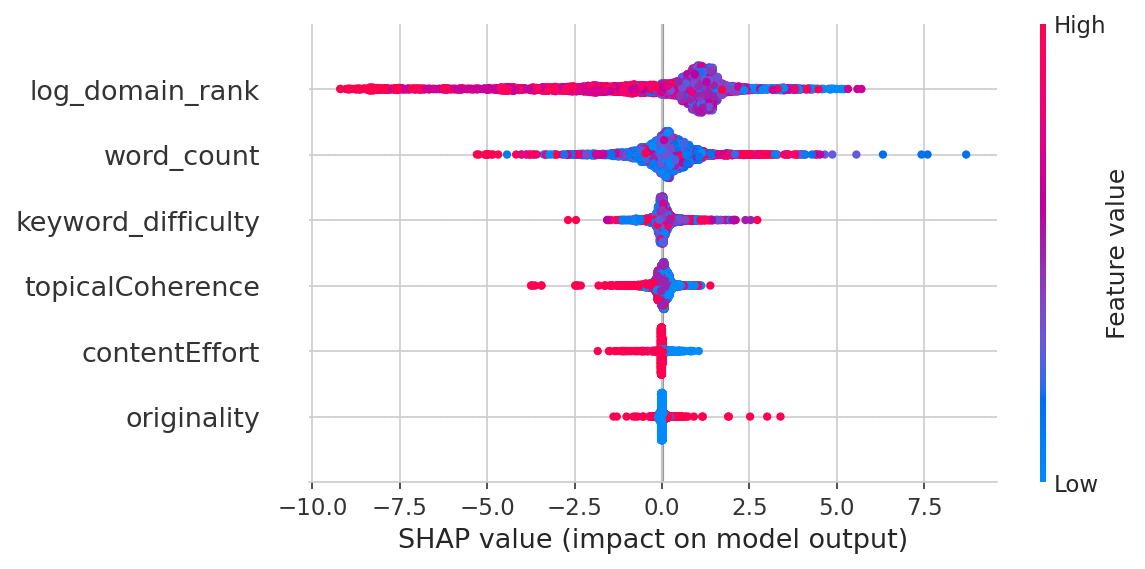
La autoridad de dominio por sí sola explica la mitad de la variación en el posicionamiento. La calidad del contenido en conjunto explica alrededor del 7%. Y el modelo completo solo explica el 18% de lo que sucede — el otro 82% son factores que no medí (backlinks a nivel de página, engagement del usuario, Core Web Vitals, señales de marca, etc.). Para ponerlo en contexto, los estudios publicados sobre factores de posicionamiento en SEO suelen reportar valores R² de 0.10-0.25. Ningún modelo explica la mayoría de las decisiones de posicionamiento de Google — si lo hiciera, todos estaríamos jubilados.
Pero ese 7% es real y consistente
En los 8 métodos, la señal se mantiene:
| Método | Hallazgo | valor p |
|---|---|---|
| Spearman (sin controlar) | Coherencia temática: ρ = -0.057 | p < 0.001 |
| Spearman parcial (controlando AD) | Sigue ahí: ρ = -0.017 | p < 0.001 |
| Análisis intra-palabra clave | Mediana ρ = -0.066, la calidad predice el rango en el 60.5% de las palabras clave | IC Bootstrap: [-0.080, -0.051] |
| Prueba de permutación | 11 desviaciones estándar respecto al nulo | p < 0.001 |
| Modelo de efectos mixtos | -0.23 posiciones por punto de coherencia | p < 0.001 |
| OLS agrupado | -0.51 posiciones por punto compuesto | p < 0.001 |
| Regresión logística (top-10) | +4.7% de probabilidad por punto de coherencia | p < 0.001 |
La prueba de permutación —que no hace suposiciones distribucionales y maneja correctamente el anidamiento— pone esto fuera de toda duda.
El efecto de la coherencia temática
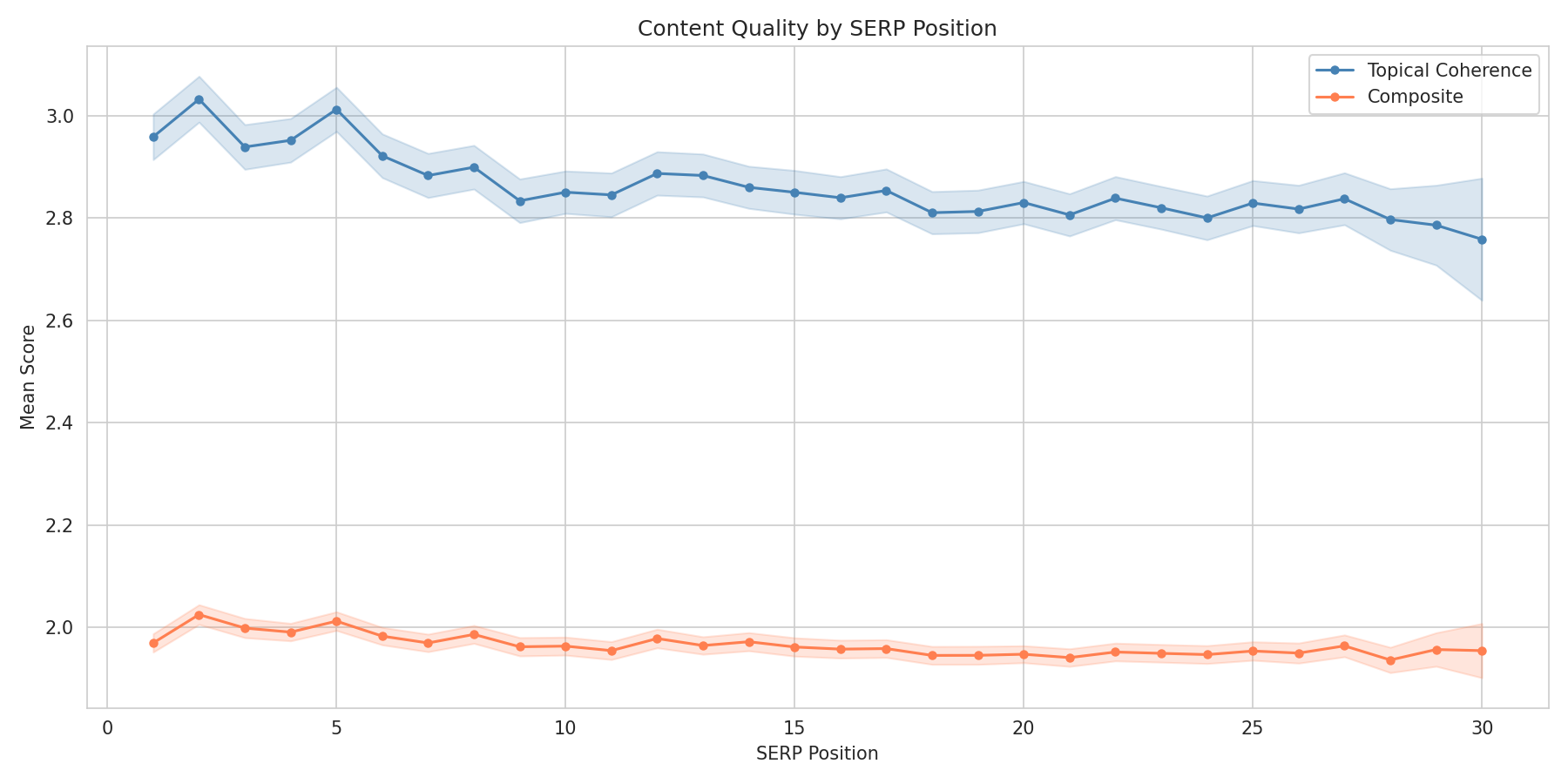
De las tres dimensiones, la coherencia temática mostró el vínculo más claro con el posicionamiento. Las páginas que se mantienen en el tema posicionan mejor que las que intentan cubrirlo todo.
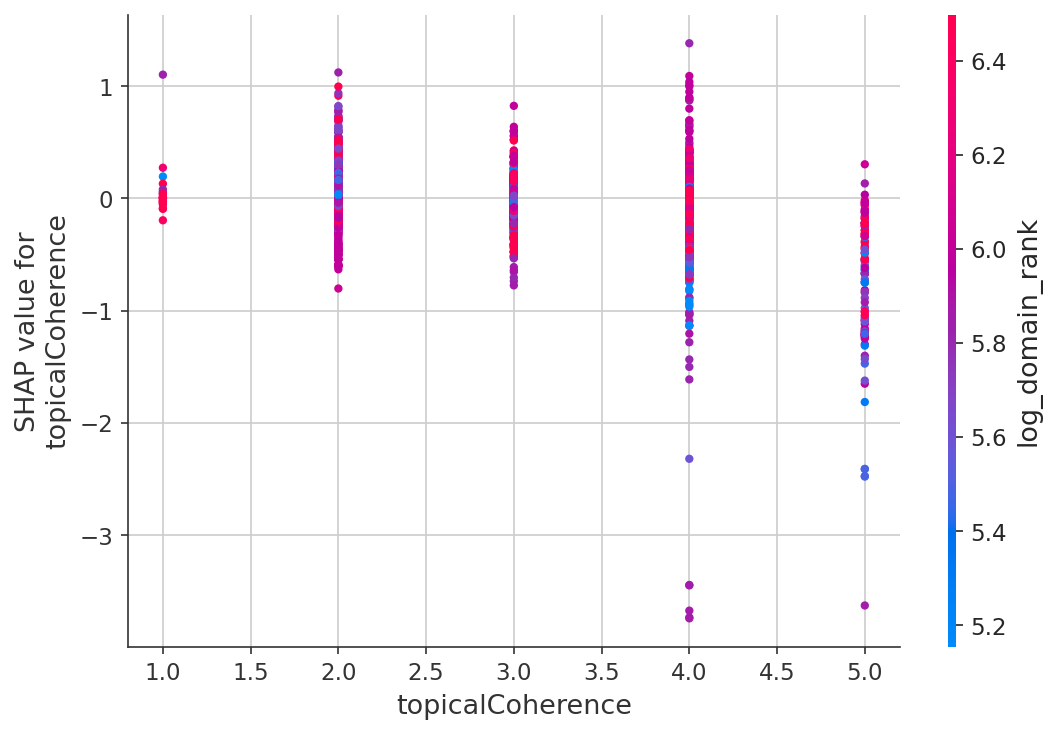
| Puntuación de Coherencia Temática | Posición Media | Tasa Top-10 |
|---|---|---|
| 1 (Incoherente) | 15.27 | 32.0% |
| 2 (Poco Enfocada) | 14.53 | 34.9% |
| 3 (Adecuada) | 14.27 | 36.1% |
| 4 (Bien Enfocada) | 13.52 | 40.2% |
| 5 (Altamente Enfocada) | 12.27 | 47.2% |
Una página que puntúa 5 en coherencia temática tiene una tasa del 47.2% de estar en el top-10, frente al 32.0% para la puntuación 1 — una diferencia de 15 puntos porcentuales. Advertencia justa: N=980 para la puntuación 5 y N=338 para la 1, así que esas estimaciones extremas tienen intervalos de confianza más amplios que las puntuaciones intermedias.
Los matices que importan
La calidad del contenido importa más cuando no tienes autoridad
Este fue el hallazgo más interesante. Dividí los datos por cuartiles de autoridad de dominio:
| Autoridad de Dominio | Coherencia → Posición ρ | ¿Significativo? |
|---|---|---|
| Q1 (autoridad más baja) | ρ = -0.059 | Sí (p < 0.001) |
| Q2 | ρ = -0.035 | Sí (p < 0.001) |
| Q3 | ρ = +0.018 | No |
| Q4 (autoridad más alta) | ρ = +0.011 | No |
![]()
Para dominios de baja autoridad, la calidad del contenido es un diferenciador real. Para dominios de alta autoridad, apenas importa — posicionan de todos modos.
En pocas palabras: Si eres Forbes, puedes publicar contenido mediocre y aun así posicionar. Si eres una startup, la calidad del contenido es una de las pocas palancas que realmente tienes.
Lo que haría con un presupuesto mayor: Usé la autoridad a nivel de dominio porque los datos de backlinks a nivel de página para 44.000 URLs estaban fuera de mi presupuesto (puede que retome esto en el futuro). La autoridad de dominio es un instrumento contundente — te dice que el sitio es fuerte, no si esta página específica ha ganado enlaces. Con conteos de dominios referentes a nivel de página, podría probar si el contenido de alto esfuerzo atrae más backlinks a nivel de página, y si el efecto calidad → posicionamiento funciona a través de la adquisición de enlaces en lugar de ser una señal directa. Eso es algo que quiero analizar a continuación.
En las palabras clave informativas es donde importa el contenido
Probé si el efecto difiere según la intención de búsqueda:
| Intención | ρ Intra-Palabra Clave | % Palabras Clave que Muestran Efecto |
|---|---|---|
| Solo informativas | -0.101 | 65% |
| Comerciales + Informativas | -0.041 | 56% |
La diferencia es clara (prueba z de Fisher, p < 0.001). La calidad del contenido importa 2.5 veces más para consultas informativas que para las comerciales.
Las palabras clave fáciles premian más la calidad
| Dificultad de Palabra Clave | ρ Intra-Palabra Clave | % Negativo |
|---|---|---|
| KD 0-20 (fácil) | -0.080 | 63% |
| KD 21-40 | -0.081 | 64% |
| KD 41-60 | -0.048 | 56% |
| KD 61+ (difícil) | -0.007 | 51% |
Para palabras clave competitivas, la autoridad domina tan completamente que la calidad del contenido casi no tiene efecto. Para palabras clave de baja competencia, la calidad sí importa.
Lo que no funciona: el relleno de palabras clave
Una advertencia aquí es que el BM25 de Google, que asumimos es la puerta de relevancia para ser incluido en el índice principal para un término de búsqueda, ha evolucionado a lo largo de los años. Mientras ejecutaba las puntuaciones BM25 básicas (relevancia/densidad de palabras clave) encontré algo que no esperaba:
| Banda de Posición | Puntuación BM25 Media |
|---|---|
| Top 1-5 | 3.950 |
| 6-10 | 3.967 |
| 11-20 | 4.016 |
| 21-30 | 4.056 |
Las páginas mejor posicionadas tienen una densidad de palabras clave ligeramente menor. El análisis intra-palabra clave lo confirmó: BM25 se correlaciona positivamente con la posición (ρ = +0.045), lo que significa que las páginas más cargadas de palabras clave posicionan peor.
Tiene sentido cuando lo piensas. Las páginas mejor posicionadas suelen ser dominios autorizados que cubren temas de forma natural. Las páginas de posiciones más bajas suelen ser páginas de servicios sobreoptimizadas que martillean la palabra clave.
---## Lo que esto significa para la estrategia de contenidos
Para muchos SEOs esto es un poco un
"o sea que me estás diciendo que el agua moja"
momento, y tendrías razón.
Si tienes baja autoridad de dominio (< Mediana)
- La calidad del contenido es una de tus mejores palancas. Un artículo bien enfocado y coherente tiene una oportunidad mediblemente mejor de posicionarse que un contenido disperso y poco enfocado.
- La coherencia temática es lo más importante. Elige UN tema por página y cúbrelo adecuadamente. No intentes posicionarte para cinco palabras clave con una sola "guía definitiva".
- Apunta a palabras clave informativas, de baja KD. Ahí es donde la calidad del contenido tiene el efecto más fuerte.
Si tienes alta autoridad de dominio
- La calidad del contenido te da rendimientos decrecientes. Tu autoridad ya te consigue posiciones. Pulir el contenido tiene un pequeño efecto marginal.
- Enfócate en el mantenimiento de la autoridad — los enlaces de calidad, la marca, las señales de confianza importan más que reescribir artículos.
Para todos
- Deja de hacer keyword stuffing. Es ligeramente contraproducente.
- El enfoque vence al esfuerzo. Una página enfocada y coherente supera en posiciones a una larga y dispersa, incluso si la dispersa requirió más trabajo para producirse.
¿Y el esfuerzo de contenido?
Este merece su propia discusión. No encontré una correlación significativa entre las puntuaciones de esfuerzo de contenido y el posicionamiento dentro del rango normal (puntuaciones 1-2). Pero el 84% de las páginas obtuvo un 2 y el 14% un 1; básicamente estaba comparando "bajo esfuerzo" con "muy bajo esfuerzo". Solo el 1.8% de las páginas en el top 30 tenían datos propios, investigación original o experiencia documentada.
Esto no es realmente un hallazgo sobre si el esfuerzo importa. Es un hallazgo sobre lo raro que es el esfuerzo genuino. El contenido de gran esfuerzo es tan poco común en los resultados de búsqueda que simplemente no tenía suficiente para medir el efecto.
Mi hipótesis de trabajo —que estos datos no pueden probar pero no contradicen— es que el efecto del esfuerzo en el posicionamiento se lava a través de los backlinks. El contenido de gran esfuerzo (datos originales, entrevistas a expertos, investigación propia) es citable. El contenido citable atrae enlaces. Los enlaces construyen autoridad de dominio. Y la autoridad de dominio es el factor de posicionamiento dominante. Por lo tanto, el esfuerzo podría importar enormemente, pero su efecto aparece en la métrica de autoridad en lugar de como una señal de calidad independiente.
Si tuviera (Cuando tenga) datos de backlinks a nivel de página (en lugar de solo a nivel de dominio), podría probar si las páginas de gran esfuerzo atraen más dominios de referencia. Ese es el próximo estudio. Mi presunción es que están altamente correlacionados.
Originalidad: La Web es Derivativa
El 86% de las páginas posicionadas en el top 30 obtuvo un 1 en originalidad — completamente derivativo. Eso no es un error en la puntuación. Haz la prueba de Google tú mismo: busca cualquier consulta informativa, lee los 10 primeros resultados y cuenta cuántos contienen una sola afirmación que no puedas encontrar en los otros 9. Casi ninguno.
El listón para una originalidad "por encima del promedio" es sorprendentemente bajo. Google no parece penalizar mucho el contenido derivativo — o si lo hace, la penalización ya está incorporada en la señal de autoridad (contenido original → citaciones → enlaces → autoridad).
Mi opinión es que a medida que los LLM asuman más y más responsabilidades en la escritura de contenido, los datos nuevos y únicos combinados con la demostración de perspicacia basada en la experiencia serán más un factor decisivo, pero la pregunta es ¿cómo pueden Google, etc., medir esto a escala?
Limitaciones
Este estudio tiene limitaciones reales de las que vale la pena ser transparente:
- La puntuación por LLM es un proxy. MiMo-V2-Flash puntuó estas páginas, no los evaluadores de calidad de Google. Las puntuaciones de los LLM son estimaciones ruidosas, aunque la validación piloto (ρ = 0.766, κ = 0.747 vs línea base Opus) sugiere que son razonablemente consistentes.
- Distribuciones de puntuación comprimidas. El 84% de las páginas obtuvo un 2 en Esfuerzo de Contenido y el 86% un 1 en Originalidad. Eso no es un defecto de la puntuación; es un reflejo exacto de la web. Casi ningún contenido que se posiciona contiene datos propios o investigación original. Pero limita el poder estadístico para esos criterios. La Coherencia Temática tuvo la distribución más amplia (41% puntuación 2, 30% puntuación 3, 25% puntuación 4) y mostró la señal más fuerte, en parte porque es la dimensión en la que las páginas realmente difieren entre sí.
- Diseño transversal. Medí posiciones y calidad en un punto en el tiempo. No puedo probar que mejorar la calidad del contenido causa mejoras en el posicionamiento, solo que la calidad y la posición están asociadas.
- Factores de confusión no medidos. Controlé la autoridad de dominio, el recuento de palabras y la dificultad de la palabra clave, pero muchos factores de posicionamiento no se midieron: velocidad de obtención de backlinks, interacción del usuario, Core Web Vitals, velocidad de la página, búsquedas de marca, etc. La autoridad de dominio y el recuento de palabras también probablemente están correlacionados (los sitios con alta autoridad producen contenido más largo), por lo que la importancia del 31.6% del recuento de palabras como característica puede ser en parte un proxy de la autoridad.
- Calidad de la extracción de contenido. rs-trafilatura maneja bien los artículos (F1 0.93) pero puede extraer mal páginas de productos o SPAs, añadiendo ruido para algunos tipos de página.
- BM25 básico. Usé Okapi BM25 básico sin ponderación de campos, puntuación por proximidad o puntuación a nivel de pasaje. Una implementación BM25F alineada con las patentes de Google probablemente mostraría resultados diferentes.
- Comparaciones múltiples. Ejecuté más de 50 pruebas a través de métodos, criterios y subgrupos. Algunos hallazgos en los márgenes podrían no sobrevivir a una corrección de Bonferroni. Los hallazgos principales — el efecto de coherencia temática, la interacción por cuartil de DA, la diferencia por intención — se mantienen en múltiples métodos independientes con tamaños de efecto consistentes.
Detalles de la metodología
Recopilación de datos
- Palabras clave: 2,212 palabras clave de EE. UU. de Ahrefs, filtradas a intención Informativa + Comercial, consultas no comerciales en el vertical de desarrollo de software.
- Datos de SERP: API de Serper (3 páginas de 10 por palabra clave = top 30 resultados).
- Descarga de HTML: httpx concurrente (94%), recurso de respaldo Playwright para páginas renderizadas con JS (4%).
- Extracción de contenido: rs-trafilatura (Rust, precisión F1 0.966).
- Autoridad de dominio: API DataForSEO Backlinks Summary (rango a nivel de dominio, escala 0-1000).
Puntuación
- Modelo: Xiaomi MiMo-V2-Flash (309B MoE, 15B parámetros activos) vía OpenRouter.
- 3 criterios × 44,465 páginas = 133,395 llamadas a la API.
- Coste total de puntuación por LLM: ~$87.
Análisis estadístico
- 8 métodos independientes con resultados consistentes.
- Método principal: análisis de rango Spearman intra-palabra clave con IC de bootstrap y prueba de permutación.
- Todo el código disponible en el repositorio de investigación.
Google-Algorithmus-Leak (Mai 2024)
Die in dieser Studie verwendeten Content-Quality-Signale – contentEffort, originalContentScore, page2vecLq – wurden aus geleakten internen Dokumenten der Google API identifiziert:
- King, M. (2024). "An Exploration of the Google Ranking Algorithm Leak." iPullRank. https://ipullrank.com/google-algo-leak
- Erste Analyse der versehentlich öffentlich gemachten Dokumente zum Google Content API Warehouse (2.596 Module, 14.014 Attribute).
- Anderson, S. (2024). "The contentEffort Attribute, The Helpful Content System and E-E-A-T — Is Gemini Behind the HCU?" Hobo Web. https://www.hobo-web.co.uk/the-contenteffort-attribute-the-helpful-content-system-and-e-e-a-t-is-gemini-behind-the-hcu/
- Detaillierte Analyse der Beziehung zwischen dem Attribut
contentEffortund dem Helpful-Content-System. - Fishkin, R. (2024). "An Anonymous Source Shared Thousands of Leaked Google Search API Documents with Me; Everyone in SEO Should See Them." SparkToro. https://sparktoro.com/blog/an-anonymous-source-shared-thousands-of-leaked-google-search-api-documents-with-me-everyone-in-seo-should-see-them/
- Unabhängige Veröffentlichung, die die Authentizität des Leaks bestätigte.
- Google (2024). Content API Warehouse-Dokumentation (Repository yoshi-code-bot/google-api-java-client-services, später gelöscht). Originalquelle, die die Definition des
googleapi.contentwarehouse-Moduls enthielt.
BM25 und gewichtete Feldsuche
- Robertson, S.E., Walker, S., Jones, S., Hancock-Beaulieu, M., & Gatford, M. (1995). "Okapi at TREC-3." In Proceedings of the Third Text REtrieval Conference (TREC-3). NIST.
- Grundlagenarbeit, die die BM25-Ranking-Funktion vorstellt, die für die Keyword-Relevanzanalyse dieser Studie verwendet wurde.
- Robertson, S.E., Zaragoza, H., & Taylor, M. (2004). "Simple BM25 Extension to Multiple Weighted Fields." In Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management (CIKM '04), pp. 42-49. https://doi.org/10.1145/1031171.1031181
- Stellt BM25F vor, eine feldgewichtete Erweiterung, die unterschiedliche Gewichte für Felder wie Titel, Haupttext und Ankertext ermöglicht. Es wird angenommen, dass die grundlegende Suchschicht von Google eine Variante dieser Technik verwendet.
- Robertson, S.E. & Zaragoza, H. (2009). "The Probabilistic Relevance Framework: BM25 and Beyond." Foundations and Trends in Information Retrieval, 3(4), pp. 333-389. https://doi.org/10.1561/1500000019
- Umfassende Untersuchung von BM25-Varianten, einschließlich BM25F, BM25+ und Näherungserweiterungen.
Google Passage Ranking
- Nayak, P. (2020). "How AI is powering a more helpful Google." Google Blog, 15. Oktober 2020. https://blog.google/products/search/search-on/
- Ankündigung des Passage-based Ranking. Ermöglicht es Google, einzelne Passagen innerhalb eines Dokuments zu bewerten, anstatt die gesamte Seite, was die Suchgenauigkeit bei langen Inhalten verbessert.
- Google Search Central (2021). "Passage Ranking launch." Februar 2021.
- Bestätigt das globale Rollout der passagenbasierten Indizierung. Verändert die Suchgrundlage, um für bestimmte Suchanfragen auf Passagen- statt auf Dokumentenebene zu bewerten.
Richtlinien für Qualitätsbewerter und E-E-A-T
- Google (2024). "Google Search Quality Evaluator Guidelines." Datiert März 2024. https://guidelines.raterhub.com/searchqualityevaluatorguidelines.pdf
- Offizielle Richtlinien, die von Googles menschlichen Qualitätsbewertern verwendet werden. Definieren die Kriterien für Expertise, Erfahrung, Autorität und Vertrauenswürdigkeit (E-E-A-T).
Tools und Datenquellen
-
rs-trafilatura
-
Rust-Portierung der Content-Extraction-Bibliothek trafilatura. Wird für die HTML-zu-Markdown-Konvertierung mit Entfernung von Boilerplate-Inhalt verwendet. F1-Score von 0,966 auf Article-Extraction-Benchmarks. 7-mal schneller als die Go-Implementierung.
-
Crawl4AI
-
Open-Source-Webcrawler und -Scraper mit LLM-Unterstützung. Wird für das Herunterladen von Seiten mit JavaScript-Unterstützung in der Wiederholungsphase via Playwright verwendet.
-
Serper API
-
Anbieter von Google-SERP-Daten. https://serper.dev
-
Wird verwendet, um die Top-30 organischen Suchergebnisse für jedes Keyword abzurufen.
-
DataForSEO Backlinks API
-
Domain-Autoritäts- und Backlink-Metriken. https://dataforseo.com
-
Wird verwendet, um den Domain-Rang (PageRank-Proxy, Skala 0-1000), die Anzahl der Backlinks und die Anzahl der verweisenden Domains zu erhalten.
-
MiMo-V2-Flash – 309B-Parameter (15B aktiv) Mixture-of-Experts-Modell von Xiaomi. Zugriff über OpenRouter. https://github.com/xiaomimimo/MiMo-V2-Flash
-
Wird für die groß angelegte Bewertung der Inhaltsqualität verwendet (Input 0,09 $/M Tokens, Output 0,29 $/M Tokens).
-
Claude Opus 4.6
-
Reasoning-Modell von Anthropic. Wird als Referenz für die Kalibrierung der LLM-Bewertung verwendet (Pilottest mit 150 Seiten).
Statistische Methoden
- Cohen, J. (1960). "A Coefficient of Agreement for Nominal Scales." Educational and Psychological Measurement, 20(1), pp. 37-46.
- Cohens Kappa, verwendet zur Berechnung der Interrater-Übereinstimmung bei der Validierung der LLM-Bewertung.
- Spearman, C. (1904). "The Proof and Measurement of Association between Two Things." The American Journal of Psychology, 15(1), pp. 72-101.
- Spearmans Rangkorrelation. Hauptstatistische Methode, die durchgehend in dieser Studie verwendet wird.
- Lundberg, S.M. & Lee, S.I. (2017). "A Unified Approach to Interpreting Model Predictions." In Advances in Neural Information Processing Systems 30 (NeurIPS 2017). https://arxiv.org/abs/1705.07874
- SHAP-Werte (SHapley Additive exPlanations). Werden für die Analyse der Merkmalswichtigkeit im Random-Forest-Modell verwendet.