Sagt die Inhaltsqualität tatsächlich Google-Rankings voraus? Ich analysierte 44.000 Seiten, um es herauszufinden.

Ich habe 44.465 SERP-Ergebnisse über 2.212 US-Keywords mit LLM-basierten Content-Quality-Rubriken bewertet und dann getestet, ob diese Bewertungen Google-Rankings vorhersagen, nachdem die Domain-Authority kontrolliert wurde. Hier ist, was ich herausgefunden habe.
Die Frage, die niemand mit Daten beantworten kann
Die SEO-Branche lebt von einem Glaubenssatz: Erstelle großartigen Content und du wirst ranken. Die eigenen Richtlinien von Google sagen dasselbe. Aber wenn man fragt: „Wie wichtig ist die Content-Qualität tatsächlich im Vergleich zur Domain-Authority?“ — niemand hat die Daten.
Ich habe beschlossen, das herauszufinden.
Was ich gemacht habe
Ich habe eine Pipeline aufgebaut, um eine einfache Hypothese zu testen:
H1: Nach Kontrolle der Domain-Authority sind Content-Quality-Bewertungen negativ mit der SERP-Position korreliert (höhere Qualität → höheres Ranking).
Der Datensatz
- 2.212 US-Keywords von Ahrefs (informationale + kommerzielle Absicht, nicht markenbezogen)
- Top-30-Ergebnisse für jedes Keyword über die Serper API
- 60.409 SERP-Ergebnisse gecrawlt und mit rs-trafilatura in Markdown extrahiert
- 44.465 Seiten bewertet nach Filterung nach Extraktionsqualität
- Domain-Authority für 8.169 eindeutige Domains über die DataForSEO Backlinks API
Die Bewertung
Bevor ich etwas in großem Maßstab bewertet habe, führte ich einen Pilotversuch mit 150 Seiten durch, bei dem MiMo-V2-Flash mit Claude Opus 4.6 verglichen wurde. Die Übereinstimmung war stark (Spearman ρ = 0,766, Cohens κ = 0,747), also machte ich weiter. Jede Seite wurde in drei Dimensionen bewertet:
| Rubrik | Basiert auf | Was wird gemessen? |
|---|---|---|
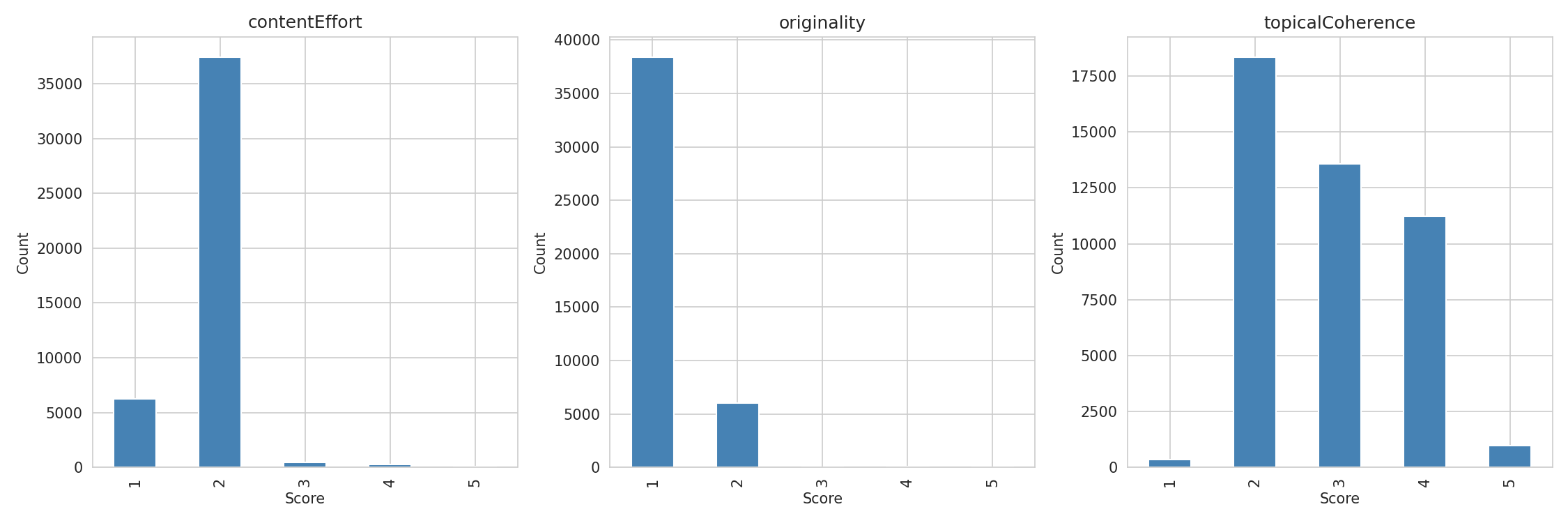
| Content Effort | Googles geleaktes contentEffort-Signal | Wie viel echte Mühe wurde investiert? Könnte eine KI es in Minuten replizieren? |
| Originalität | Googles geleaktes originalContentScore-Signal | Fügt dies neues Wissen hinzu oder reorganisiert es nur bereits Bekanntes? |
| Topical Coherence | Googles page2vecLq-Signal | Dient jeder Abschnitt dem Kernthema oder schweift die Seite ab? |
Jede Rubrik wurde mit 1-5 bewertet, mit Kalibrierungsregeln, ausgearbeiteten Beispielen und Fallen für falsch-positive Ergebnisse, die ich über mehrere Kundenprojekte verfeinert habe. Die Rubriken, nicht das Modell, leisten die Hauptarbeit — die Bewertungs-Prompts sind so detailliert, dass jedes leistungsfähige LLM ähnliche Ergebnisse liefert, weshalb der Pilotversuch eine starke Übereinstimmung über zwei sehr verschiedene Modelle zeigte. Ich habe die vollständigen Rubriken mit ausgearbeiteten Beispielen separat veröffentlicht, wenn Sie Ihren eigenen Content bewerten möchten.
Ein Hinweis zur statistischen Signifikanz
Mit 44.000 Beobachtungen ist statistische Signifikanz trivial einfach zu erreichen — selbst winzige, bedeutungslose Effekte zeigen p < 0,001. Deshalb konzentriere ich mich auf Effektstärken, praktische Signifikanz und ob die Ergebnisse über mehrere Methoden hinweg bestehen und nicht auf p-Werte. Wenn der Effekt in der Praxis nicht groß genug ist, um wichtig zu sein, ist es mir egal, dass er „statistisch signifikant“ ist.
Die Methoden
Ich habe mich nicht auf einen einzigen Test verlassen. Ich habe 8 unabhängige Methoden zur Triangulation verwendet. Die Methoden 3 und 5 behandeln die geschachtelte Struktur korrekt (mehrere Seiten, die für das gleiche Keyword konkurrieren, sind nicht unabhängig); die anderen nicht, daher kommen ihre p-Werte mit dieser Einschränkung:
- Spearman-Rangkorrelation
- Partielle Spearman (unter Kontrolle der Domain-Authority)
- Within-Keyword-Ranganalyse (Vergleich von Seiten, die für die gleiche Abfrage konkurrieren)
- Permutationstest (1.000 Shuffles für Goldstandard-p-Werte)
- Lineares gemischtes Modell (behandelt Schachtelung)
- OLS mit geclusterten Standardfehlern
- Logistische Regression für Top-10-Wahrscheinlichkeit
- Random Forest mit SHAP-Feature-Importance
Die Ergebnisse
Ja, Content-Qualität sagt Rankings voraus — aber wie viel?
Alle 8 Methoden zeigten in die gleiche Richtung. Content-Qualität ist mit höheren Rankings assoziiert, selbst nach Kontrolle der Domain-Authority.
Aber die Effektstärke ist hier wichtig, nicht die p-Werte.
Domain-Authority ist 10-mal wichtiger
Der Random Forest (trainiert auf 35.621 Seiten, validiert auf 8.844 zurückgehaltenen Seiten, R² = 0,178) macht es deutlich:
| Feature | Importance |
|---|---|
| Domain Authority | 49,7 % |
| Wortanzahl | 31,6 % |
| Keyword-Schwierigkeit | 11,8 % |
| Thematische Kohärenz | 3,7 % |
| Content-Aufwand | 1,7 % |
| Originalität | 1,5 % |
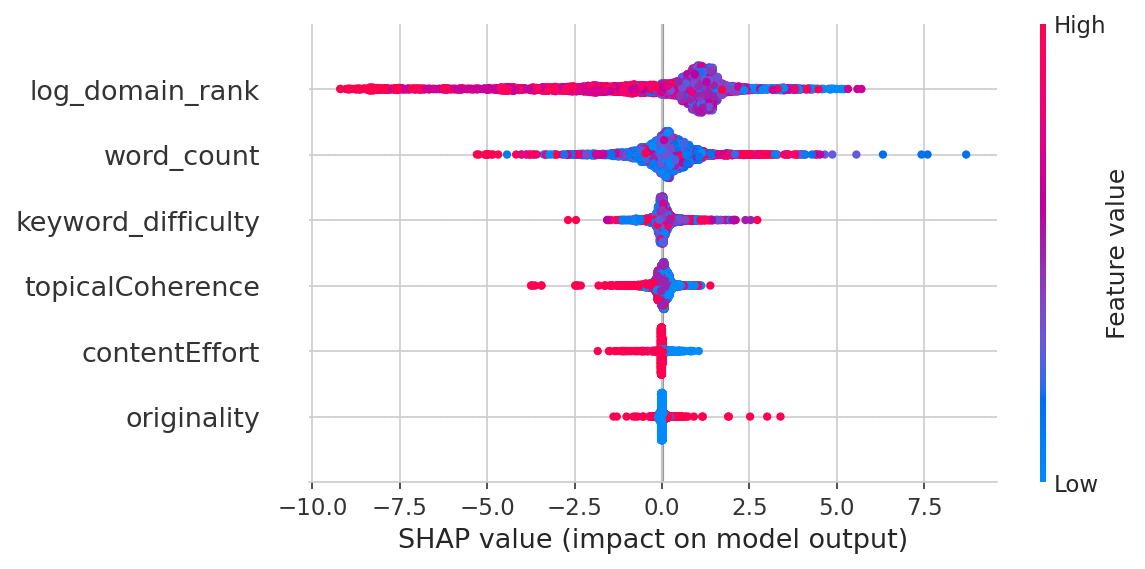
Domain-Authority allein macht die Hälfte der Variation in den Rankings aus. Content-Qualität insgesamt macht etwa 7 % aus. Und das vollständige Modell erklärt nur 18 % von dem, was passiert — die anderen 82 % sind Faktoren, die ich nicht gemessen habe (Backlinks auf Seitenebene, Nutzerinteraktion, Core Web Vitals, Brandsignale usw.). Zum Kontext: Veröffentlichte SEO-Rankingfaktor-Studien berichten typischerweise von R²-Werten von 0,10–0,25. Kein Modell erklärt den Großteil von Googles Rankingentscheidungen — wenn doch, wären wir alle im Ruhestand.
Aber diese 7 % sind real und konsistent
Über alle 8 Methoden hinweg hält das Signal stand:
| Methode | Ergebnis | p-Wert |
|---|---|---|
| Spearman (roh) | Thematische Kohärenz: ρ = -0,057 | p < 0,001 |
| Partielle Spearman (unter Kontrolle der DA) | Immer noch da: ρ = -0,017 | p < 0,001 |
| Within-Keyword-Analyse | Median ρ = -0,066, Qualität sagt Rang in 60,5 % der Keywords voraus | Bootstrap CI: [-0,080, -0,051] |
| Permutationstest | 11 Standardabweichungen von der Null | p < 0,001 |
| Gemischtes Modell | -0,23 Positionen pro Kohärenzpunkt | p < 0,001 |
| OLS geclustert | -0,51 Positionen pro Composite-Punkt | p < 0,001 |
| Logistisch (Top-10) | +4,7 % Odds pro Kohärenzpunkt | p < 0,001 |
Der Permutationstest — der keine Verteilungsannahmen macht und die Schachtelung korrekt behandelt — stellt dies außer Zweifel.
Der Effekt der thematischen Kohärenz
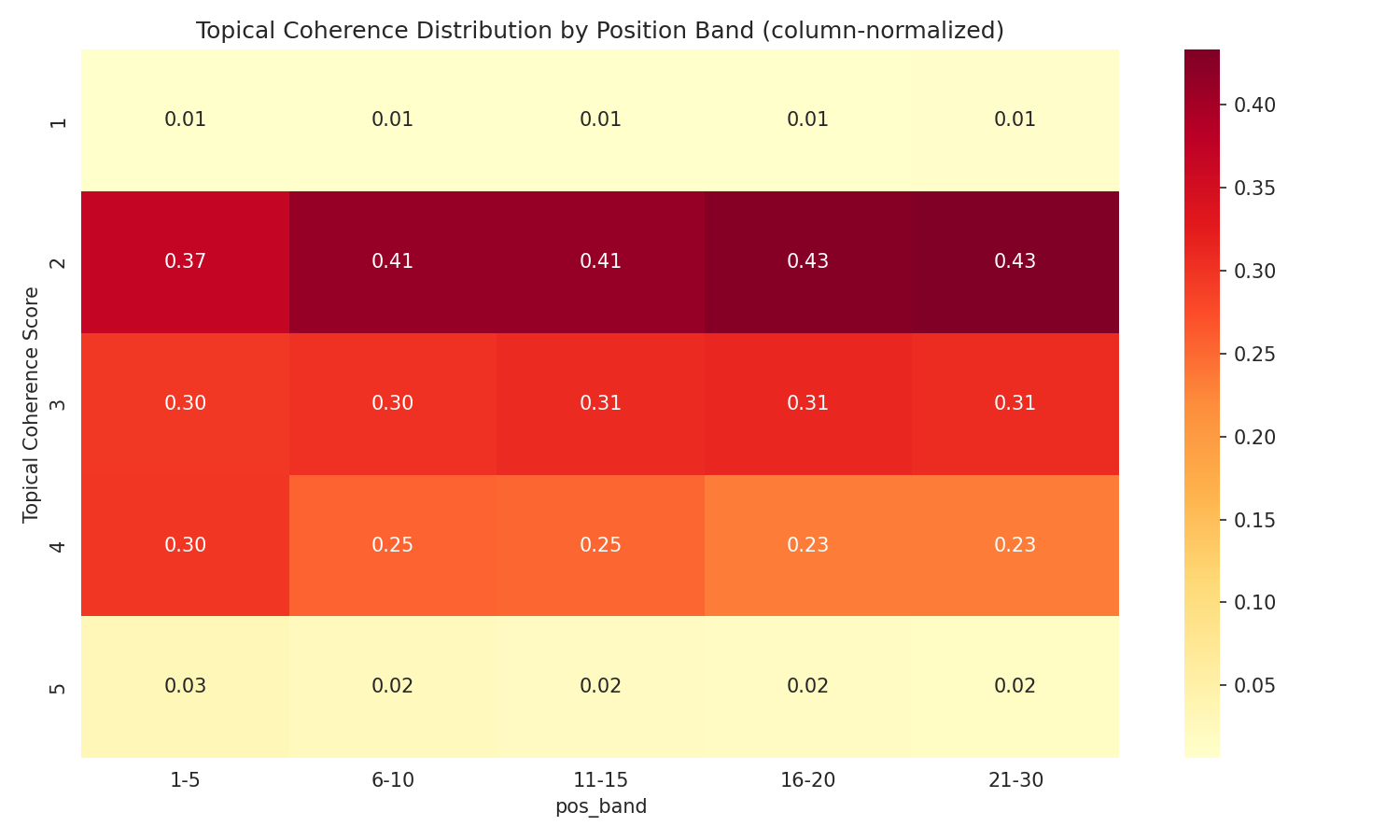
Von den drei Dimensionen zeigte thematische Kohärenz den klarsten Zusammenhang mit dem Ranking. Seiten, die beim Thema bleiben, ranken höher als Seiten, die alles abdecken wollen.
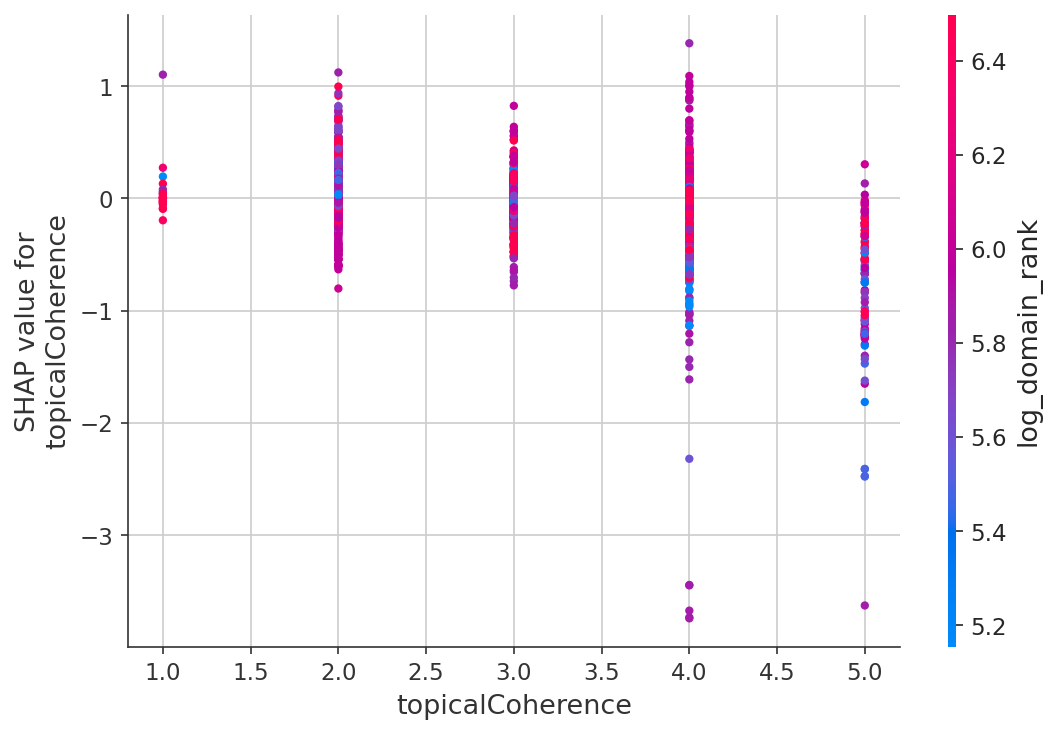
| Topical Coherence Score | Mittlere## Was das für die Content-Strategie bedeutet
Für viele SEOs ist das ein bisschen ein
"Willst du damit sagen, Wasser ist nass?"
Moment, und damit hättet ihr recht.
Wenn du eine niedrige Domain Authority hast (< Median)
- Die Inhaltsqualität ist einer deiner besten Hebel. Ein gut fokussierter, zusammenhängender Artikel hat eine messbar bessere Chance zu ranken als verstreuter, unfokussierter Content.
- Thematische Kohärenz ist am wichtigsten. Wähle EIN Thema pro Seite und behandle es ordentlich. Versuche nicht, mit einem einzigen "Ultimate Guide" für fünf Keywords zu ranken.
- Ziele auf informative Keywords mit niedriger Keyword Difficulty ab. Dort hat die Inhaltsqualität die stärkste Wirkung.
Wenn du eine hohe Domain Authority hast
- Die Inhaltsqualität bringt dir abnehmende Grenzerträge. Deine Autorität sorgt bereits dafür, dass du rankst. Das Optimieren von Inhalten hat nur einen geringen zusätzlichen Effekt.
- Konzentriere dich auf den Erhalt der Autorität
- Backlinks, Marke, Vertrauenssignale sind wichtiger als das Umschreiben von Artikeln.
Für alle
- Hör auf mit Keyword-Stuffing. Es ist leicht kontraproduktiv.
- Fokus schlägt Aufwand. Eine fokussierte, zusammenhängende Seite outrankt eine lange, unstrukturierte – selbst wenn die unstrukturierte mehr Arbeit in der Erstellung gekostet hat.
Was ist mit dem Inhaltsaufwand?
Dieser Punkt verdient eine eigene Betrachtung. Ich fand keine signifikante Korrelation zwischen den Content-Effort-Scores und dem Ranking im normalen Bereich (Scores 1-2). Aber 84 % der Seiten hatten Score 2 und 14 % Score 1 – ich habe im Grunde "geringen Aufwand" mit "sehr geringem Aufwand" verglichen. Nur 1,8 % der Seiten in den Top 30 enthielten proprietäre Daten, eigene Recherchen oder dokumentierte Expertise.
Das ist keine wirkliche Erkenntnis darüber, ob Aufwand wichtig ist. Es ist eine Erkenntnis darüber, wie selten echter Aufwand ist. Hochwertiger, aufwändiger Content ist in den Suchergebnissen so ungewöhnlich, dass ich schlicht nicht genug davon hatte, um den Effekt zu messen.
Meine Arbeitshypothese – die diese Daten nicht beweisen, aber auch nicht widerlegen – ist, dass der Ranking-Effekt von Aufwand über Backlinks abgewickelt wird. Aufwändiger Content (Originaldaten, Experteninterviews, eigene Forschung) ist zitierfähig. Zitierfähiger Content zieht Links an. Links bauen Domain Authority auf. Und Domain Authority ist der dominierende Rankingfaktor. Also könnte Aufwand enorm wichtig sein, aber sein Effekt zeigt sich in der Autoritätsmetrik und nicht als unabhängiges Qualitätssignal.
Wenn ich Backlink-Daten auf Seitenebene hätte (statt nur auf Domainebene), könnte ich testen, ob aufwändige Seiten mehr verweisende Domains anziehen. Das ist die nächste Studie. Ich gehe davon aus, dass diese stark korrelieren.
Originalität: Das Web ist derivativ
86 % der Seiten, die in den Top 30 rankten, hatten die Originalitätsbewertung 1 – vollständig derivativ. Das ist kein Fehler in der Bewertung. Mach den Google-Test selbst: Suche nach einer beliebigen informativen Suchanfrage, lies die Top-10-Ergebnisse und zähle, wie viele eine einzige Aussage enthalten, die du in den anderen 9 nicht findest. Fast keine.
Die Latte für "überdurchschnittliche" Originalität ist erschreckend niedrig. Google scheint derivative Inhalte nicht stark zu bestrafen – oder wenn doch, ist die Strafe bereits im Autoritätssignal enthalten (originaler Content → Zitate → Links → Autorität).
Meine Ansicht ist, dass, wenn LLMs mehr und mehr der Inhaltserstellung übernehmen, neue und einzigartige Datenpunkte gepaart mit demonstrierter Erkenntnis aus Erfahrung eher zu einem entscheidenden Faktor werden. Die Frage ist nur, wie Google usw. das im großen Maßstab messen kann?
Einschränkungen
Diese Studie hat echte Einschränkungen, über die es sich lohnt, offen zu sprechen:
- Die LLM-Bewertung ist ein Proxy. MiMo-V2-Flash hat diese Seiten bewertet, nicht die Quality Rater von Google. LLM-Scores sind verrauschte Schätzwerte, auch wenn die Pilotvalidierung (ρ = 0,766, κ = 0,747 vs. Opus-Baseline) darauf hindeutet, dass sie recht konsistent sind.
- Komprimierte Score-Verteilungen. 84 % der Seiten hatten beim Content Effort Score 2 und 86 % bei der Originalität Score 1. Das ist kein Bewertungsfehler – es ist eine genaue Widerspiegelung des Webs. Fast kein rankender Content enthält proprietäre Daten oder eigene Forschung. Aber es schränkt die statistische Aussagekraft für diese Rubriken ein. Thematische Kohärenz hatte die breiteste Verteilung (41 % Score 2, 30 % Score 3, 25 % Score 4) und zeigte das stärkste Signal – zum Teil, weil es die Dimension ist, in der sich Seiten tatsächlich voneinander unterscheiden.
- Querschnittsdesign. Ich habe Rankings und Qualität zu einem Zeitpunkt gemessen. Kann nicht beweisen, dass die Verbesserung der Inhaltsqualität Ranking-Verbesserungen verursacht – nur, dass Qualität und Rank assoziiert sind.
- Nicht gemessene Störfaktoren. Ich habe Domain Authority, Wortanzahl und Keyword Difficulty kontrolliert, aber viele Rankingfaktoren wurden nicht gemessen: Backlink-Velocity, Nutzer-Engagement, Core Web Vitals, Seitenladegeschwindigkeit, Brandsuchen usw. Domain Authority und Wortanzahl sind wahrscheinlich auch korreliert (Websites mit hoher Autorität produzieren längere Inhalte), daher mag die Feature Importance der Wortanzahl von 31,6 % zum Teil für Autorität stehen.
- Qualität der Inhalts-Extraktion. rs-trafilatura verarbeitet Artikel gut (F1 0,93), kann aber Produktseiten oder SPAs falsch extrahieren, was für einige Seitentypen Rauschen hinzufügt.
- Standard-BM25. Ich habe einfachen Okapi BM25 ohne Feldgewichtung, Näherungsbewertung (Proximity Scoring) oder Passage-Level-Bewertung verwendet. Eine BM25F-Implementierung, die mit Googles Patenten übereinstimmt, würde wahrscheinlich andere Ergebnisse zeigen.
- Multiple Vergleiche. Ich habe 50+ Tests über Methoden, Rubriken und Untergruppen hinweg durchgeführt. Einige Randbefunde könnten eine Bonferroni-Korrektur nicht überstehen. Die Kernbefunde
- Effekt der thematischen Kohärenz, DA-Quartil-Interaktion, Intent-Unterschied – halten mehreren unabhängigen Methoden mit konsistenten Effektstärken stand.
Methodik-Details
Datenerfassung
- Keywords: 2.212 US-Keywords von Ahrefs, gefiltert auf informational + kommerzielle Intention, nicht gebrandete Suchanfragen im Vertical Softwareentwicklung
- SERP-Daten: Serper API (3 Seiten à 10 pro Keyword = Top 30 Ergebnisse)
- HTML-Download: httpx concurrent (94 %), Playwright-Fallback für JS-gerenderte Seiten (4 %)
- Inhalts-Extraktion: rs-trafilatura (Rust, F1 0,966 Genauigkeit)
- Domain Authority: DataForSEO Backlinks Summary API (Domain-Level Rank, 0-1000 Skala)
Bewertung
- Modell: Xiaomi MiMo-V2-Flash (309B MoE, 15B aktive Parameter) via OpenRouter
- 3 Rubriken × 44.465 Seiten = 133.395 API-Calls
- Gesamtkosten für LLM-Bewertung: ~87 $
Statistische Analyse
- 8 unabhängige Methoden mit konsistenten Ergebnissen
- Primärmethode: Within-Keyword-Spearman-Rang-Analyse mit Bootstrap-KI und Permutationstest
- Der gesamte Code ist im Forschungs-Repository verfügbar
Google-Algorithmus-Leak (Mai 2024)
Die in dieser Studie verwendeten Content-Quality-Signale – contentEffort, originalContentScore, page2vecLq – wurden aus geleakten internen Dokumenten der Google API identifiziert:
- King, M. (2024). "An Exploration of the Google Ranking Algorithm Leak." iPullRank. https://ipullrank.com/google-algo-leak
- Erste Analyse der versehentlich öffentlich gemachten Dokumente zum Google Content API Warehouse (2.596 Module, 14.014 Attribute).
- Anderson, S. (2024). "The contentEffort Attribute, The Helpful Content System and E-E-A-T — Is Gemini Behind the HCU?" Hobo Web. https://www.hobo-web.co.uk/the-contenteffort-attribute-the-helpful-content-system-and-e-e-a-t-is-gemini-behind-the-hcu/
- Detaillierte Analyse der Beziehung zwischen dem Attribut
contentEffortund dem Helpful-Content-System. - Fishkin, R. (2024). "An Anonymous Source Shared Thousands of Leaked Google Search API Documents with Me; Everyone in SEO Should See Them." SparkToro. https://sparktoro.com/blog/an-anonymous-source-shared-thousands-of-leaked-google-search-api-documents-with-me-everyone-in-seo-should-see-them/
- Unabhängige Veröffentlichung, die die Authentizität des Leaks bestätigte.
- Google (2024). Content API Warehouse-Dokumentation (Repository yoshi-code-bot/google-api-java-client-services, später gelöscht). Originalquelle, die die Definition des
googleapi.contentwarehouse-Moduls enthielt.
BM25 und gewichtete Feldsuche
- Robertson, S.E., Walker, S., Jones, S., Hancock-Beaulieu, M., & Gatford, M. (1995). "Okapi at TREC-3." In Proceedings of the Third Text REtrieval Conference (TREC-3). NIST.
- Grundlagenarbeit, die die BM25-Ranking-Funktion vorstellt, die für die Keyword-Relevanzanalyse dieser Studie verwendet wurde.
- Robertson, S.E., Zaragoza, H., & Taylor, M. (2004). "Simple BM25 Extension to Multiple Weighted Fields." In Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management (CIKM '04), pp. 42-49. https://doi.org/10.1145/1031171.1031181
- Stellt BM25F vor, eine feldgewichtete Erweiterung, die unterschiedliche Gewichte für Felder wie Titel, Haupttext und Ankertext ermöglicht. Es wird angenommen, dass die grundlegende Suchschicht von Google eine Variante dieser Technik verwendet.
- Robertson, S.E. & Zaragoza, H. (2009). "The Probabilistic Relevance Framework: BM25 and Beyond." Foundations and Trends in Information Retrieval, 3(4), pp. 333-389. https://doi.org/10.1561/1500000019
- Umfassende Untersuchung von BM25-Varianten, einschließlich BM25F, BM25+ und Näherungserweiterungen.
Google Passage Ranking
- Nayak, P. (2020). "How AI is powering a more helpful Google." Google Blog, 15. Oktober 2020. https://blog.google/products/search/search-on/
- Ankündigung des Passage-based Ranking. Ermöglicht es Google, einzelne Passagen innerhalb eines Dokuments zu bewerten, anstatt die gesamte Seite, was die Suchgenauigkeit bei langen Inhalten verbessert.
- Google Search Central (2021). "Passage Ranking launch." Februar 2021.
- Bestätigt das globale Rollout der passagenbasierten Indizierung. Verändert die Suchgrundlage, um für bestimmte Suchanfragen auf Passagen- statt auf Dokumentenebene zu bewerten.
Richtlinien für Qualitätsbewerter und E-E-A-T
- Google (2024). "Google Search Quality Evaluator Guidelines." Datiert März 2024. https://guidelines.raterhub.com/searchqualityevaluatorguidelines.pdf
- Offizielle Richtlinien, die von Googles menschlichen Qualitätsbewertern verwendet werden. Definieren die Kriterien für Expertise, Erfahrung, Autorität und Vertrauenswürdigkeit (E-E-A-T).
Tools und Datenquellen
-
rs-trafilatura
-
Rust-Portierung der Content-Extraction-Bibliothek trafilatura. Wird für die HTML-zu-Markdown-Konvertierung mit Entfernung von Boilerplate-Inhalt verwendet. F1-Score von 0,966 auf Article-Extraction-Benchmarks. 7-mal schneller als die Go-Implementierung.
-
Crawl4AI
-
Open-Source-Webcrawler und -Scraper mit LLM-Unterstützung. Wird für das Herunterladen von Seiten mit JavaScript-Unterstützung in der Wiederholungsphase via Playwright verwendet.
-
Serper API
-
Anbieter von Google-SERP-Daten. https://serper.dev
-
Wird verwendet, um die Top-30 organischen Suchergebnisse für jedes Keyword abzurufen.
-
DataForSEO Backlinks API
-
Domain-Autoritäts- und Backlink-Metriken. https://dataforseo.com
-
Wird verwendet, um den Domain-Rang (PageRank-Proxy, Skala 0-1000), die Anzahl der Backlinks und die Anzahl der verweisenden Domains zu erhalten.
-
MiMo-V2-Flash – 309B-Parameter (15B aktiv) Mixture-of-Experts-Modell von Xiaomi. Zugriff über OpenRouter. https://github.com/xiaomimimo/MiMo-V2-Flash
-
Wird für die groß angelegte Bewertung der Inhaltsqualität verwendet (Input 0,09 $/M Tokens, Output 0,29 $/M Tokens).
-
Claude Opus 4.6
-
Reasoning-Modell von Anthropic. Wird als Referenz für die Kalibrierung der LLM-Bewertung verwendet (Pilottest mit 150 Seiten).
Statistische Methoden
- Cohen, J. (1960). "A Coefficient of Agreement for Nominal Scales." Educational and Psychological Measurement, 20(1), pp. 37-46.
- Cohens Kappa, verwendet zur Berechnung der Interrater-Übereinstimmung bei der Validierung der LLM-Bewertung.
- Spearman, C. (1904). "The Proof and Measurement of Association between Two Things." The American Journal of Psychology, 15(1), pp. 72-101.
- Spearmans Rangkorrelation. Hauptstatistische Methode, die durchgehend in dieser Studie verwendet wird.
- Lundberg, S.M. & Lee, S.I. (2017). "A Unified Approach to Interpreting Model Predictions." In Advances in Neural Information Processing Systems 30 (NeurIPS 2017). https://arxiv.org/abs/1705.07874
- SHAP-Werte (SHapley Additive exPlanations). Werden für die Analyse der Merkmalswichtigkeit im Random-Forest-Modell verwendet.